三层 Web 应用程序具有表示层、应用程序层和数据库层。
这种熟悉的模式为学习 AWS 云开发工具包 (CDK) 等新技术提供了肥沃的土壤。
在本教程中,我们将使用 DynamoDB 表、HTTP API 端点、Lambda 处理程序和带有 CloudFront 内容分发网络 (CDN) 的前端 React 应用程序创建一个简单的笔记应用程序。
所有这些都可以使用单个命令部署到 AWS 账户。并且所有这些都将用 TypeScript 编写。
本教程的源代码可在 GitHub .
如何获取 AWS 账户凭证
首先,我们需要一个 AWS 账户和命令行中可用的凭证。本教程中部署的所有资源都应保留在免费使用层级中,但仍需要使用信用卡来注册 AWS 账户。
如果您还没有 AWS 账户, 这里 有一个很好的资源,可以帮助您安全地创建账户并遵循最佳实践。
AWS 新手可能还希望查看 CDK 研讨会 AWS 帐户和用户的 部分 .
其他先决条件
使用 AWS 时,最好安装 AWS CLI 。您还需要 安装 Node.js。
如何初始化应用程序
首先,我们可以使用 cdk 命令行实用程序来构建应用程序。
-
mkdir cdk-three-tier-serverless && cd cdk-three-tier-serverless -
npx cdk init app --language=typescript
这将创建一些文件来帮助我们开始并下载必要的依赖项。
CDK v1 与 v2 — 有什么区别?
AWS CDK v2 正式发布。AWS 已宣布 v1 将 进入维护阶段,并最终 于 2023 年 6 月终止对 v1 的支持。v1 和 v2 之间的主要区别在于 v2 在管理依赖项方面做得更好。为 v1 构建的已发布构造需要更新,然后才能在 v2 应用程序中运行。
Projen 是什么?(可选)
Projen 在 CDK 社区中很受欢迎,是 的替代品 cdk init 。为了避免引入过多概念,本教程不使用 projen,但你可以从以下开始创建一个非常相似的应用程序 npx projen new awscdk-app-ts .
如何启动你的 AWS 账户
为了将我们的 AWS 账户与 AWS CDK 一起使用,我们必须首先通过部署一个简单的堆栈来引导该账户,以管理账户中的资产。
您可以通过 npx cdk bootstrap 在命令行中输入来执行此操作。最好 后 操作,否则引导程序会要求提供其他信息。如果引导成功,我们就可以继续构建我们的应用程序了,否则,我们应该参考官方 文档 获取故障排除建议。
如何引导 AWS 角色(可选)
引导程序将创建多个角色,可用于部署、管理资产和查找资源 Amazon 资源名称 (ARN)。虽然您可以使用具有 AdministratorAccess 策略的用户完成本教程,但这不是最佳实践。
如果我们查找引导程序创建的角色的 ARN,我们可以构建细粒度的策略并将其应用于新用户。
我们创建的策略可能看起来像这样。请参阅 有关创建 IAM 用户的 官方文档
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "assumecdkroles",
"Effect": "Allow",
"Action": [
"sts:AssumeRole",
"iam:PassRole"
],
"Resource": [
"arn:aws:iam::1234567890:role/cdk-abc123-deploy-role-1234567890-us-east-1",
"arn:aws:iam::1234567890:role/cdk-abc123-file-publishing-role-1234567890-us-east-1",
"arn:aws:iam::1234567890:role/cdk-abc123-image-publishing-role-1234567890-us-east-1",
"arn:aws:iam::1234567890:role/cdk-abc123-lookup-role-1234567890-us-east-1"
]
}
]
}类似这样的策略,在锁定 MFA 和根访问权限的账户中,应该可以为学习者提供合理的安全程度。企业用户需要考虑设置 AWS SSO 和 AWS 组织 .
如何构建数据层
我们将从构建数据层开始。我们将能够逐步部署我们的应用程序并在 AWS 控制台中检查进度。
如何创建 DynamoDB 表
init 操作将创建一个名为 cdk-three-tier-serverless-stack.ts 的文件。我们可以从那里开始构建我们的应用程序。首先,让我们删除注释代码并添加表声明。请注意,与 CDK v1 应用程序不同,无需安装其他软件包即可开始使用 DynamoDB。
import { RemovalPolicy, Stack, StackProps } from 'aws-cdk-lib';
import { AttributeType, BillingMode, Table } from 'aws-cdk-lib/aws-dynamodb';
import { Construct } from 'constructs';
export class CdkThreeTierServerlessStack extends Stack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props);
const table = new Table(this, 'NotesTable', {
billingMode: BillingMode.PAY_PER_REQUEST,
partitionKey: { name: 'pk', type: AttributeType.STRING },
removalPolicy: RemovalPolicy.DESTROY,
sortKey: { name: 'sk', type: AttributeType.STRING },
tableName: 'NotesTable',
});
}
}
我们可以立即使用该表进行部署 npx cdk deploy ,然后在控制台中检查它。
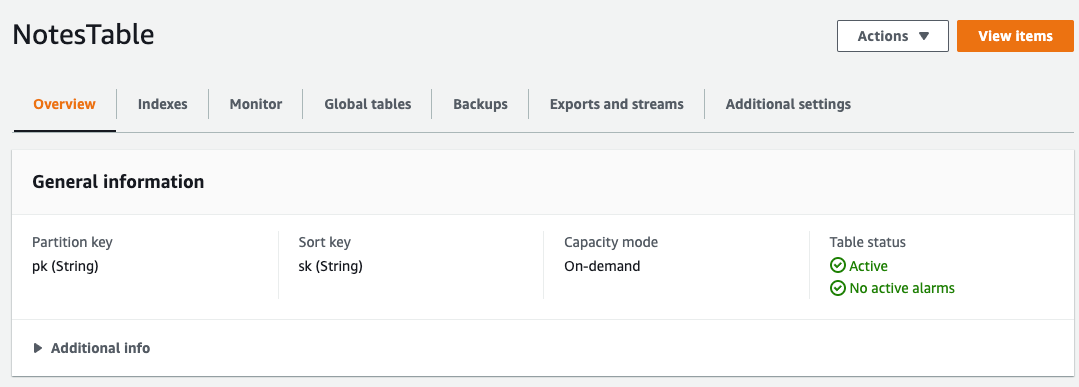
如何使用 AWS DynamoDB OneTable 建模数据
OneTable 是一款用于管理 DynamoDB 查询的工具。其背后的理念是,可以在同一个 DynamoDB 表中对多个不同的实体进行建模,这一做法得到了该领域许多专家的认可。
在我们的简单应用程序中,我们只有单个实体注释,但我们无论如何都会使用 OneTable,因为它将有助于管理我们的架构。由于 DynamoDB 是 NoSQL 数据库,因此架构不是在创建表时定义的,而是在应用程序代码中定义的。
首先,我们需要安装依赖项。
npm i @aws-sdk/client-dynamodb dynamodb-onetable我们马上要创建两个 Lambda 函数,并希望在它们之间共享一个模型。我们可以按照自己喜欢的方式组织代码。让我们在 lib 下创建一个 \'fns\' 文件夹,并创建名为 notesTable.ts、readFunction.ts 和 writeFunction.ts 的文件。

我们可以在 notesTable.ts 中定义一个模式。
import { DynamoDBClient } from '@aws-sdk/client-dynamodb';
import { Entity, Table } from 'dynamodb-onetable';
import Dynamo from 'dynamodb-onetable/Dynamo';
const client = new Dynamo({ client: new DynamoDBClient({}) });
const schema = {
indexes: {
primary: {
hash: 'pk',
sort: 'sk',
},
},
models: {
note: {
type: {
required: true,
type: 'string',
value: 'note',
},
pk: {
type: 'string',
value: 'note',
},
sk: {
type: 'string',
value: '${date}',
},
note: {
required: true,
type: 'string',
},
date: {
required: true,
type: 'string',
},
subject: {
required: true,
type: 'string',
},
},
},
version: '0.1.0',
params: {
typeField: 'type',
},
format: 'onetable:1.0.0',
} as const;
export type NoteType = Entity;
const table = new Table({
client,
name: 'NotesTable',
schema,
timestamps: true,
});
export const Notes = table.getModel('note'); 我们正在为模型定义“type”、“subject”、“note”和“date”属性。所有这些属性都将具有字符串类型。我们还将指出分区键将始终设置为“note”。这对于小型示例应用程序来说很好,但对于较大的应用程序,根据应用程序所需的查询类型或访问模式,使用用户 ID 或帐户 ID 之类的值是有意义的。
排序键和日期字段将包含完全相同的数据。这种数据复制是一种最佳实践,因为它允许我们在表中拥有不同类型的实体,其中一些实体可能不按日期排序。
应用层
我们的应用程序层将由一些 Lambda 函数和一个将它们连接到互联网的 API 网关组成。
Lambda 处理程序
现在我们将填写 Lambda 处理程序。我们可以添加额外的类型,以便更轻松地在 TypeScript 环境中工作。
npm i -D @types/aws-lambda由于 OneTable 消除了处理 DynamoDB 的大量复杂性,我们的 Lambda 处理程序非常简单。我们的读取函数执行查找操作并返回结果。
import type { APIGatewayProxyResultV2 } from 'aws-lambda';
import { Notes } from './notesTable';
export const handler = async (): Promise => {
const notes = await Notes.find({ pk: 'note' }, { limit: 10, reverse: true });
return { body: JSON.stringify(notes), statusCode: 200 };
}; 添加限制和反向参数意味着查询将返回最近的十条注释,并按排序键自动排序。
我们的写入函数同样非常简单。
import type {
APIGatewayProxyEventV2,
APIGatewayProxyResultV2,
} from 'aws-lambda';
import { Notes } from './notesTable';
export const handler = async (
event: APIGatewayProxyEventV2
): Promise => {
const body = event.body;
if (body) {
const notes = await Notes.create(JSON.parse(body));
return { body: JSON.stringify(notes), statusCode: 200 };
}
return { body: 'Error, invalid input!', statusCode: 400 };
}; NodejsFunction 构造
回到我们的堆栈,我们现在需要创建函数构造。我们的 Lambda 函数将用 TypeScript 编写,因此在它们可以在 Lambda 运行时中运行之前,需要进行转译步骤。
幸运的是,CDK 提供了一个 NodejsFunction 结构来帮我们解决这个问题。NodejsFunction 使用 esbuild ,这是一种非常快的转译器。esbuild 不是 CDK 的直接依赖项,因此我们需要安装它以避免较慢的回退,它在 Docker 中构建。
npm i -D esbuild
现在我们可以将构造添加到堆栈中。
import { RemovalPolicy, Stack, StackProps } from 'aws-cdk-lib';
import { AttributeType, BillingMode, Table } from 'aws-cdk-lib/aws-dynamodb';
import { Architecture } from 'aws-cdk-lib/aws-lambda';
import { NodejsFunction } from 'aws-cdk-lib/aws-lambda-nodejs';
import { RetentionDays } from 'aws-cdk-lib/aws-logs';
import { Construct } from 'constructs';
export class CdkThreeTierServerlessStack extends Stack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props);
const table = new Table(this, 'NotesTable', {
billingMode: BillingMode.PAY_PER_REQUEST,
partitionKey: { name: 'pk', type: AttributeType.STRING },
removalPolicy: RemovalPolicy.DESTROY,
sortKey: { name: 'sk', type: AttributeType.STRING },
tableName: 'NotesTable',
});
const readFunction = new NodejsFunction(this, 'ReadNotesFn', {
architecture: Architecture.ARM_64,
entry: `${__dirname}/fns/readFunction.ts`,
logRetention: RetentionDays.ONE_WEEK,
});
const writeFunction = new NodejsFunction(this, 'WriteNoteFn', {
architecture: Architecture.ARM_64,
entry: `${__dirname}/fns/writeFunction.ts`,
logRetention: RetentionDays.ONE_WEEK,
});
}
}我们的导入列表在不断增加,但所有导入都与 aws-cdk-lib 一起安装,因此无需担心版本问题。我们还需要授予函数访问表的权限。
table.grantReadData(readFunction);
table.grantWriteData(writeFunction);所有这些都可以在此阶段部署。虽然我们的功能无法通过互联网访问,但可以从 AWS 控制台执行。
Lambda 函数应该进行单元测试!编写测试超出了本教程的范围,但您可以在 源代码库 .
HTTP 接口
我们将使用 AWS API Gateway HTTP API 构建面向用户的 API。HTTP API 是 REST API 的低成本替代方案。HTTP API 的 CDK 构造仍处于试验阶段,因此我们需要安装其他模块才能使用它。
npm i @aws-cdk/aws-apigatewayv2-alpha @aws-cdk/aws-apigatewayv2-integrations-alpha然后我们可以将必要的类导入到我们的堆栈中。
import {
CorsHttpMethod,
HttpApi,
HttpMethod,
} from '@aws-cdk/aws-apigatewayv2-alpha';
import { HttpLambdaIntegration } from '@aws-cdk/aws-apigatewayv2-integrations-alpha';要创建 HTTP API,我们需要具有 CORS 配置的基本构造,因为我们的视图将由 CloudFront 域提供。然后我们创建集成构造并最终添加路由。
const api = new HttpApi(this, 'NotesApi', {
corsPreflight: {
allowHeaders: ['Content-Type'],
allowMethods: [CorsHttpMethod.GET, CorsHttpMethod.POST],
allowOrigins: ['*'],
},
});
const readIntegration = new HttpLambdaIntegration(
'ReadIntegration',
readFunction
);
const writeIntegration = new HttpLambdaIntegration(
'WriteIntegration',
writeFunction
);
api.addRoutes({
integration: readIntegration,
methods: [HttpMethod.GET],
path: '/notes',
});
api.addRoutes({
integration: writeIntegration,
methods: [HttpMethod.POST],
path: '/notes',
});API Gateway 将自动为我们的终端节点生成 URL。我们可以应用自定义域,但这需要花费一些钱,因此我们暂时将使用生成的 URL。最好从我们的堆栈中输出它,这样我们就不需要在控制台上查找它了。我们可以将 CfnOutput 添加到我们的 aws-cdk-lib 导入中,并在我们的堆栈中添加一行。
new CfnOutput(this, 'HttpApiUrl', { value: api.apiEndpoint });
现在让我们再次使用 进行部署 npx cdk deploy 。我们将获得类似这样的输出。
输出:
CdkThreeTierServerlessStack.HttpApiUrl = https://g50qzchav1.execute-api.us-east-1.amazonaws.com
我们可以立即在 Web 浏览器中打开 https://g50qzchav1.execute-api.us-east-1.amazonaws.com/notes 并查看正在运行的 API。由于数据库中尚未包含任何内容,因此我们只会返回一个空数组。我们可以使用 REST 客户端并开始发布数据,但让我们构建我们的用户界面。
捕获 API URL
为了获得更好的开发人员体验,我们实际上可以将该 URL 存储在本地配置文件中以供我们的项目使用。这可以通过将 –outputs-file 参数添加到我们的 deploy 命令中来实现。我们可以将其添加到我们的 npm 脚本中以输出 config.json。
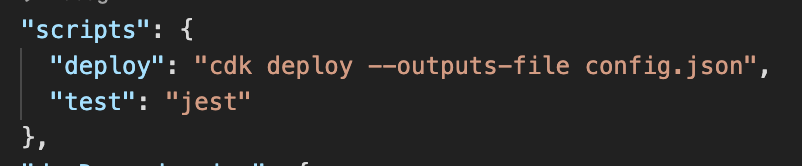
将该 config.json 文件添加到我们的 .gitignore 中可能是一个好主意。我们在源代码管理中不需要它,我们将以另一种方式管理我们部署的 Web 应用程序。
表示层
最后,让我们构建表示层。在本教程中,我们将使用 React。表示层将通过 CloudFront Distribution 提供服务,但它可以作为我们 CDK 应用程序的一部分进行构建和部署。
反应应用
全栈 TypeScript 应用程序的一个很酷的地方是,我们可以在一个地方管理所有依赖项。我们将用 TypeScript 构建一个 React 应用程序。我们将它与 esbuild 捆绑在一起并使用 vitejs ,这是一个不错的工具,它为 esbuild 添加了实时重新加载和一些其他生活质量功能。让我们添加我们的依赖项和 devDependencies。请注意,这里的区别更多是出于惯例,无论这些是依赖项还是 devDependencies,此应用程序的工作方式可能都一样。
npm i react react-dom
npm i -D @types/react @types/react-dom @vitejs/plugin-react-refresh vite按照惯例,vitejs 需要在项目的根目录中有一个 index.html,所以让我们添加它。
Three-tier Serverless Web App
index.html 直接引用了 main.tsx。让我们在 lib 下创建一个名为 web 的新目录,并在该子目录中添加 App.tsx、index.css、main.tsx 和 utils.ts。
由于我们要将 React 添加到项目中,因此我们需要修改 tsconfig.json 并添加以下键和值:
"jsx": "react",
"esModuleInterop": true,
"allowSyntheticDefaultImports": true我们还需要在 tsconfig.json 中的 \'lib\' 键中添加另一个值。
"lib": ["DOM", "es2018"],现在让我们编写 main.tsx。这是 React 应用程序的入口点,只需要调用另一个组件。
import './index.css';
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
ReactDOM.render(
,
document.getElementById('root')
);我们可以在 index.css 中添加一些 css 来启动应用程序。
body {
background-color: darkslategray;
color: antiquewhite;
font-family: 'Lucida Sans', 'Lucida Sans Regular', 'Lucida Grande',
'Lucida Sans Unicode', Geneva, Verdana, sans-serif;
font-size: 16pt;
}
button {
background-color: forestgreen;
color: white;
}
input,
textarea {
width: 200px;
}
table {
border: 1px solid;
margin: 20px;
}
td {
font-size: 12pt;
padding: 10px;
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis;
}App.tsx 开始变得有点长,可能最好分解成单独的组件,但是 React 状态管理超出了本教程的范围,所以让我们保持简单。
import React, { useEffect, useState } from 'react';
import { NoteType } from '../fns/notesTable';
import { getNotes, saveNote } from './utils';
const App = () => {
const [body, setBody] = useState('');
const [notes, setNotes] = useState([]);
const [subject, setSubject] = useState('');
useEffect(() => {
getNotes().then((n) => setNotes(n));
}, []);
const clickHandler = async () => {
if (body && subject) {
setBody('');
setSubject('');
await saveNote({
date: new Date().toISOString(),
note: body,
subject,
type: 'note',
});
const n = await getNotes();
setNotes(n);
}
};
return (
setSubject(e.target.value)}
placeholder="Note Subject"
type="text"
value={subject}
/>
Subject
Note
Date
{notes.map((note: NoteType) => (
{note.subject}
{note.note}
{new Date(note.date).toLocaleString()}
))}
);
};
export default App;我们需要在 utils.ts 中构建我们的 http 客户端。这里我们有一个额外的步骤,我们将从我们之前创建的 config.json 文件中获取该 HTTP API url。这样我们就可以拥有本地开发环境,而无需复制粘贴 URL。
import { NoteType } from '../fns/notesTable';
let url = '';
const getUrl = async () => {
if (url) {
return url;
}
const response = await fetch('./config.json');
url = `${(await response.json()).CdkThreeTierServerlessStack.HttpApiUrl}/notes`;
return url;
};
export const getNotes = async () => {
const result = await fetch(await getUrl());
return await result.json();
};
export const saveNote = async (note: NoteType) => {
await fetch(await getUrl(), {
body: JSON.stringify(note),
headers: { 'Content-Type': 'application/json' },
method: 'POST',
mode: 'cors',
});
};为了启用 react-refresh 插件,我们可以选择在项目的根目录中添加 vite.config.ts 文件,代码如下。
import { defineConfig } from 'vite';
import reactRefresh from '@vitejs/plugin-react-refresh';
// https://vitejs.dev/config/
export default defineConfig({
plugins: [reactRefresh()],
});
完成所有操作后,我们可以使用 启动开发服务器 npx vite 上查看 Web 应用程序 http://localhost:3000 。服务器将检测更改,如果我们进行更改,服务器将重新加载。我们可以尝试保存一些笔记,看看效果如何。
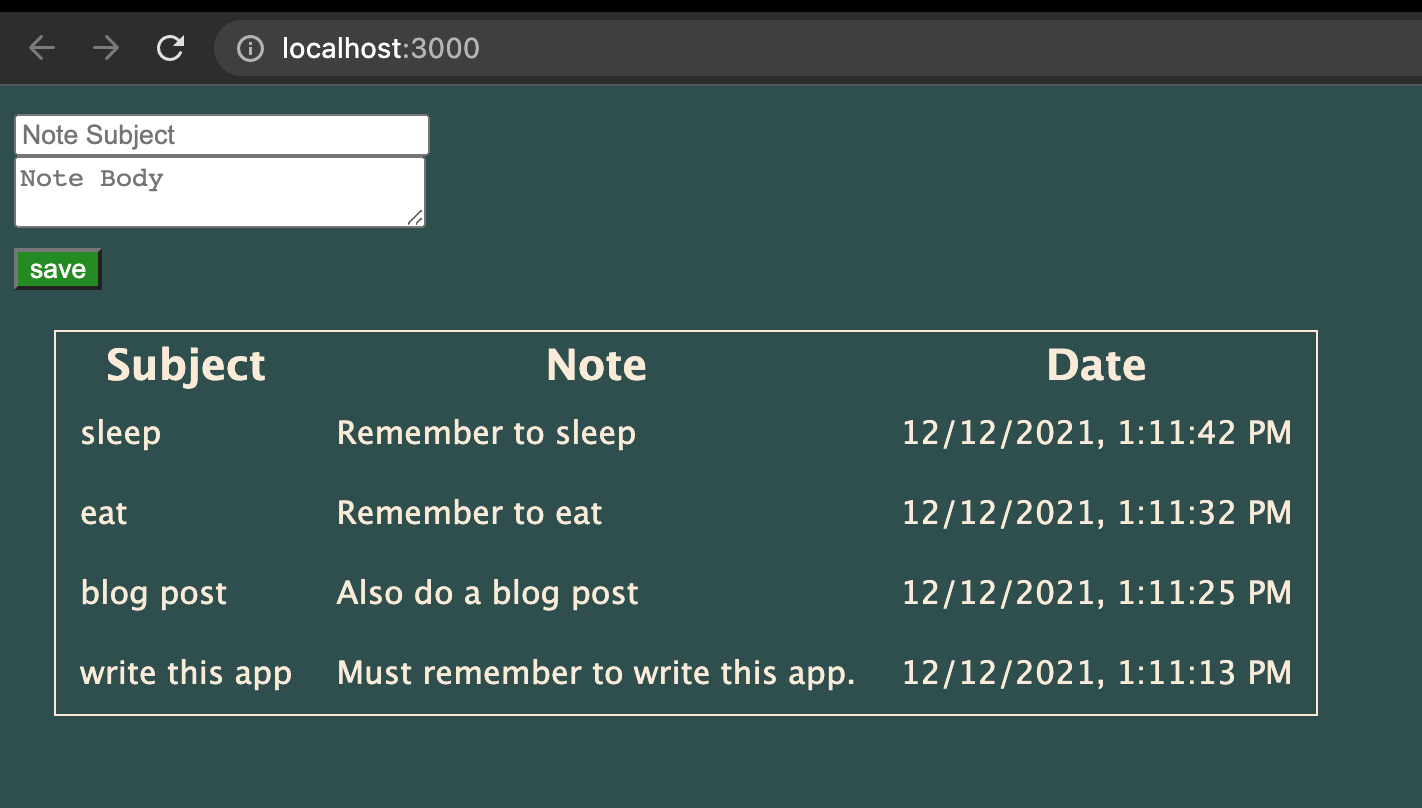
或许可以使用一些样式帮助,但除此之外,效果非常好。
CloudFront 分发
在本节中,我们将向 cdk-three-tier-serverless-stack.ts 添加更多构造。我们只需要一个额外的依赖项。此时我们的堆栈开始变得有点大,但为了本教程的目的,我们将所有内容保存在一个模块中。此时开始考虑如何分解大型模块或堆栈通常是一种很好的做法,但这个深奥的话题最好在另一个教程或博客文章中介绍。
我们的 Web 应用程序将由一个用于存储的 S3 存储桶、一个用于 React 应用程序的 CloudFront 分发和构建步骤以及一个将向 Web 应用程序提供 API URL 的自定义资源组成。
在 CDK 中创建 S3 存储桶很容易。请注意,虽然可以使用 S3 网站,但这不是 S3 网站,因为我们想使用 CloudFront 进行全球 CDN 和 https。如果我们有一个自定义域,我们也希望将其附加到我们的 CloudFront 分发版。
import { BlockPublicAccess, Bucket } from 'aws-cdk-lib/aws-s3';
const websiteBucket = new Bucket(this, 'WebsiteBucket', {
autoDeleteObjects: true,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
removalPolicy: RemovalPolicy.DESTROY,
});
我们在这里使用 autoDeleteObjects 和 RemovalPolicy.DESTROY 只是因为这是一个教程。如果您正在构建生产应用程序,您可能希望更好地保护您的资产。
此 S3 存储桶没有公共访问权限。相反,我们将通过 CloudFront Distribution 授予访问权限。为此,我们需要使用 OriginAccessIdentity 构造来授予 CloudFront 所需的读取访问权限。
import {
Distribution,
OriginAccessIdentity,
ViewerProtocolPolicy,
} from 'aws-cdk-lib/aws-cloudfront';
const originAccessIdentity = new OriginAccessIdentity(
this,
'OriginAccessIdentity'
);
websiteBucket.grantRead(originAccessIdentity);然后我们创建实际的分布。
import {
Distribution,
OriginAccessIdentity,
ViewerProtocolPolicy,
} from 'aws-cdk-lib/aws-cloudfront';
import { S3Origin } from 'aws-cdk-lib/aws-cloudfront-origins';
const distribution = new Distribution(this, 'Distribution', {
defaultBehavior: {
origin: new S3Origin(websiteBucket, { originAccessIdentity }),
viewerProtocolPolicy: ViewerProtocolPolicy.REDIRECT_TO_HTTPS,
},
defaultRootObject: 'index.html',
errorResponses: [
{
httpStatus: 404,
responseHttpStatus: 200,
responsePagePath: '/index.html',
},
],
});此分发版专为 React 等单页应用程序设计,并将所有流量升级到 https。
在下一部分中,我们将添加一个新的辅助库 fs-extra。这将使我们在应用程序中复制构建文件变得更加容易。
npm i -D @types/fs-extra fs-extra我们将使用 CDK 资产捆绑功能,通过 vitejs 和 esbuild 构建我们的 React 应用程序,作为堆栈综合过程的一部分。默认情况下,CDK 资产捆绑希望使用 Docker。由于我们已经处于 NodeJS 运行时中,因此我们更愿意绕过速度较慢的 Docker 构建,而改用本地捆绑。
import {
CfnOutput,
DockerImage,
RemovalPolicy,
Stack,
StackProps,
} from 'aws-cdk-lib';
import { execSync, ExecSyncOptions } from 'child_process';
import { join } from 'path';
import { copySync } from 'fs-extra';
const execOptions: ExecSyncOptions = {
stdio: ['ignore', process.stderr, 'inherit'],
};
const bundle = Source.asset(join(__dirname, 'web'), {
bundling: {
command: [
'sh',
'-c',
'echo "Docker build not supported. Please install esbuild."',
],
image: DockerImage.fromRegistry('alpine'),
local: {
tryBundle(outputDir: string) {
try {
execSync('esbuild --version', execOptions);
} catch {
return false;
}
execSync('npx vite build', execOptions);
copySync(join(__dirname, '../dist'), outputDir, {
...execOptions,
recursive: true,
});
return true;
},
},
},
});
捆绑程序将运行 vite build,将我们转译的 Web 应用程序放在 下 /dist ,然后它会将这些文件复制到 CDK 暂存目录(通常是 cdk.out)中。
我们将使用 BucketDeployment 来完成所有这些工作,它实际上负责将我们的更改运送到目标 S3 Bucket。
import { BucketDeployment, Source } from 'aws-cdk-lib/aws-s3-deployment';
new BucketDeployment(this, 'DeployWebsite', {
destinationBucket: websiteBucket,
distribution,
logRetention: RetentionDays.ONE_DAY,
prune: false,
sources: [bundle],
});AwsCustomResource
所有这些都很好,但我们仍然缺少一个 config.json 文件,该文件将帮助 React 应用程序了解我们的 HTTP API URL。我们可以部署一次堆栈,生成文件,然后将其捆绑并发送,但这意味着我们必须部署两次才能启动我们的应用程序。最好在第一次部署时动态生成此文件。我们可以使用 AwsCustomResource 来做到这一点。自定义资源将隐式创建一个可以接收生成的 URL 的 Lambda 函数,然后进行 AWS SDK 调用以将其存储在我们的 Web 应用程序可以找到它的 S3 中。所有这些只需几行代码即可完成!
import { AwsCustomResource, AwsCustomResourcePolicy, PhysicalResourceId } from 'aws-cdk-lib/custom-resources';
import { PolicyStatement } from 'aws-cdk-lib/aws-iam';
new AwsCustomResource(this, 'ApiUrlResource', {
logRetention: RetentionDays.ONE_DAY,
onUpdate: {
action: 'putObject',
parameters: {
Body: Stack.of(this).toJsonString({
[this.stackName]: { HttpApiUrl: api.apiEndpoint },
}),
Bucket: websiteBucket.bucketName,
CacheControl: 'max-age=0, no-cache, no-store, must-revalidate',
ContentType: 'application/json',
Key: 'config.json',
},
physicalResourceId: PhysicalResourceId.of('config'),
service: 'S3',
},
policy: AwsCustomResourcePolicy.fromStatements([
new PolicyStatement({
actions: ['s3:PutObject'],
resources: [websiteBucket.arnForObjects('config.json')],
}),
]),
});在我们再次部署之前还有一件事。现在我们有一个 CloudFront 发行版来托管我们的 React 应用程序,让我们添加另一个 CfnOutput,以便我们可以轻松获取该发行版的 URL。
new CfnOutput(this, 'DistributionDomain', {
value: distribution.distributionDomainName,
});现在我们可以访问分发 URL 并查看我们的工作应用程序!我们将看到现有的笔记,也可以添加新的笔记!
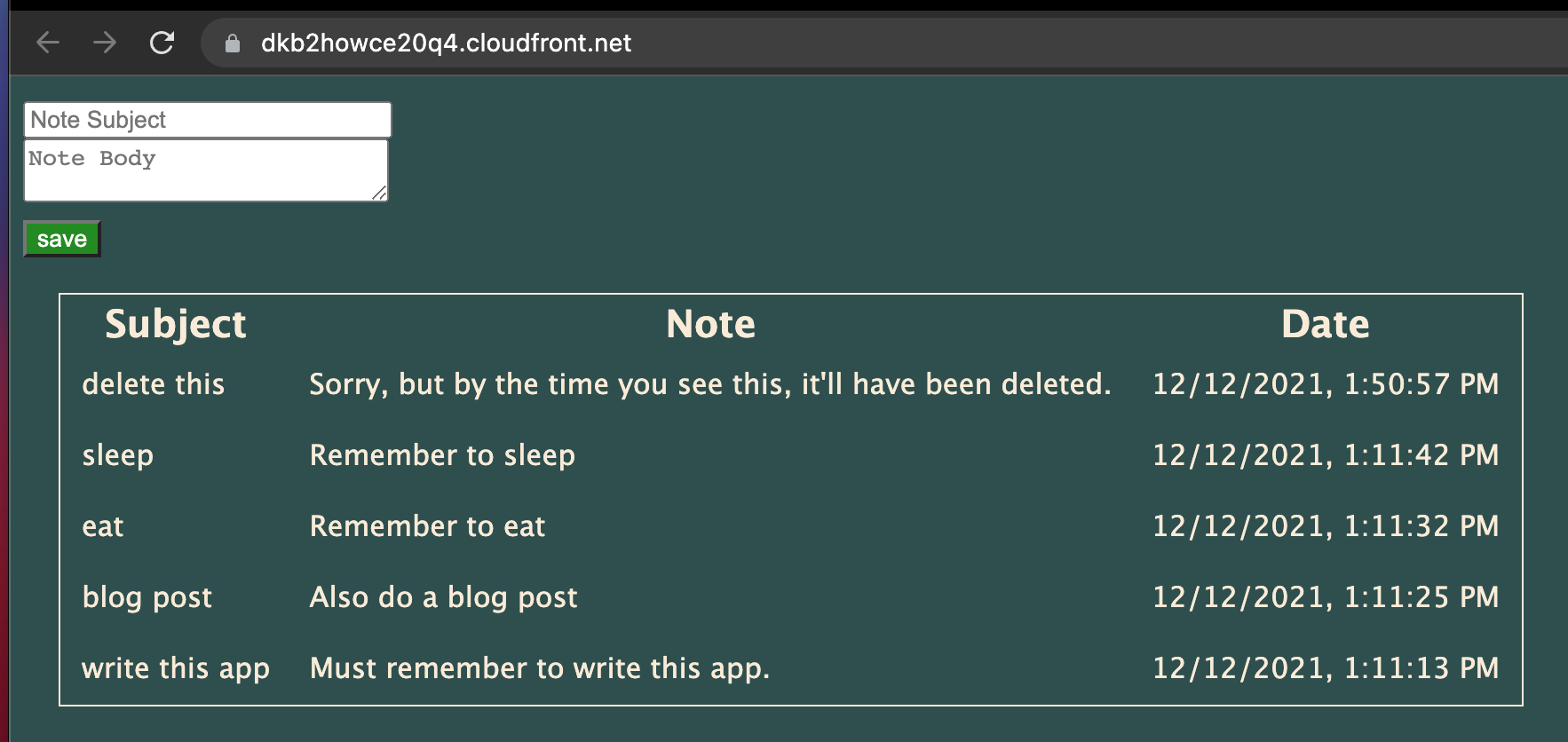
结论和后续步骤
如果您已经走到这一步并让您的应用程序正常运行,那么恭喜您!您可能希望添加其他功能,例如分页、授权,或允许用户更新或删除笔记。完成实验后,最好采纳上述建议并执行 npx cdk delete 以删除堆栈和资源,以避免产生费用。
我们介绍了使用 AWS CDK 创建三层 Web 应用程序所需的所有步骤。想要了解有关 CDK 的更多信息?加入 https://cdk.dev/ ,并查看 https://thecdkbook.com/ https://thecdkbook.com/
喜欢全栈 TypeScript 但想提高技能?那就看看我的书《 TypeScript 研讨会》 。对本教程、CDK 或 TypeScript 有疑问或意见?在 Twitter 上关注我 https://twitter.com/NullishCoalesce 或 https://mattmorgan.cloud .



发表评论 取消回复