如何使用 Python 的 pandas 库来分析时间序列数据?让我们来一探究竟。
p时间重采样as 库经常用于导入、管理和分析各种格式的数据集。在本文中,我们将使用它来分析微软前几年的股价。我们还将了解如何使用 pandas and 和 时间平移
什么是时间序列数据?
时间序列数据包含依赖于某种时间单位的值。以下都是时间序列数据的示例:
- 24 小时内每小时售出的商品数量
- 一个月内出行的乘客人数
- 每日股票价格
在所有这些中,数据都依赖于时间单位;在图中,时间显示在 x 轴上,相应的数据值显示在 y 轴上。
获取数据
我们将使用包含 2013 年至 2018 年微软股价的数据集。该数据集可从 Yahoo Finance 。您可能需要输入时间跨度来下载数据,数据将以 CSV 格式呈现。
导入所需的库
在将数据集导入应用程序之前,您需要导入所需的库。执行以下脚本即可执行此操作。
import numpy as np import pandas as pd %matplotlib inline import matplotlib.pyplot as plt
此脚本导入了 NumPy、pandas 和 matplotlib 库。这些是执行本文中的脚本所需的库。
注意: 数据集中的所有脚本均已使用 Jupyter Jupyter
导入和分析数据集
要导入数据集,我们将使用 read_csv() 方法。执行以下脚本:
stock_data = pd.read_csv('E:/Datasets/MSFT.csv')
要查看数据集的外观,可以使用 head() 方法。此方法返回数据集的前五行。
stock_data.head()
输出如下所示:
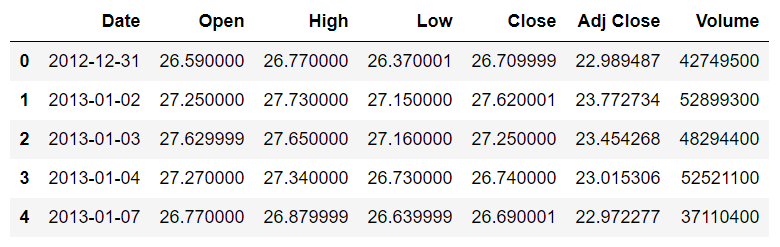
您可以看到数据集包含 Microsoft 股票的日期和开盘价、最高价、最低价、收盘价和调整后的收盘价。目前,该
Date
列被视为简单字符串。我们希望将列中的值
Date
视为日期。为此,我们需要将
Date
列转换为
日期时间
类型。以下脚本执行此操作:
stock_data['Date'] = stock_data['Date'].apply(pd.to_datetime)
最后,我们需要将 Date 列用作索引列,因为所有其他列都依赖于此列中的值。为此,请执行以下脚本:
stock_data.set_index('Date',inplace=True)
如果再次使用
head()
方法,您将看到列中的值
Date
以粗体显示,如下图所示。这是因为该
Date
列现在被视为索引列:
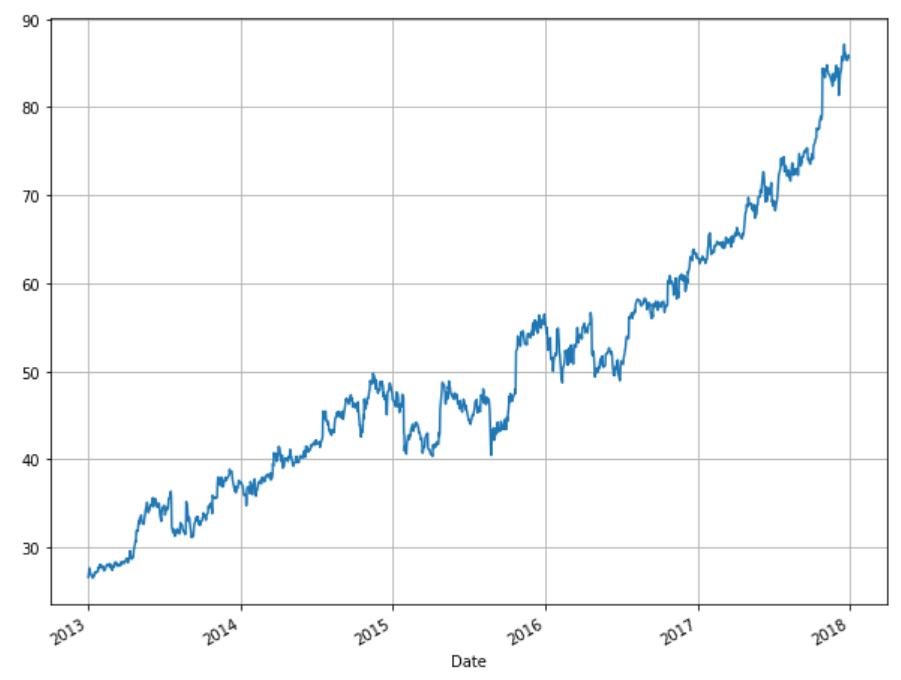
现在,让我们根据日期绘制“开盘”列的值。为此,请执行以下脚本:
plt.rcParams['figure.figsize'] = (10, 8) # Increases the Plot Size stock_data['Open'].plot(grid = True)
输出显示了 2013 年 1 月至 2017 年底的开盘股价:
接下来,我们将使用 pandas 库进行时间重采样。如果您在继续之前需要复习一下 pandas、matplotlib 或 NumPy 技能,请查看 的“ 数据科学 Python 入门” 课程。
时间重采样
时间重采样是指汇总特定时间段的时间序列数据。默认情况下,您有每天的股票价格信息。如果您想获取每年的平均股票价格信息怎么办?您可以使用时间重采样来实现这一点。
pandas 库自带 resample() 函数,可用于时间重采样。您需要做的就是为 规则 属性以及聚合函数(例如最大值、最小值、平均值等)设置偏移量。
以下是一些可用作 规则 的 resample() :
W weekly frequency M month end frequency Q quarter end frequency A year end frequency
偏移值的完整列表可以在 pandas 文档 .
现在您已经拥有了时间重采样所需的所有信息。让我们来实现它。假设您想找到所有年份的平均股票价格。为此,请执行以下脚本:
stock_data.resample(rule='A').mean()
偏移值“A”指定您想要根据年份重新采样。mean () 函数指定您想要查找平均股票价值。
输出如下所示:
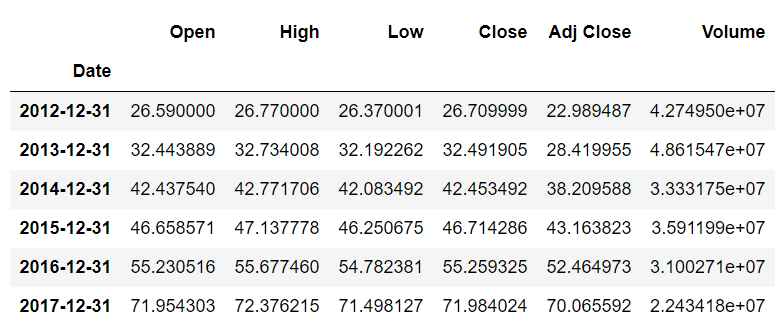
您可以看到该列的值
Date
是该年的最后一天。所有其他值都是全年的平均值。
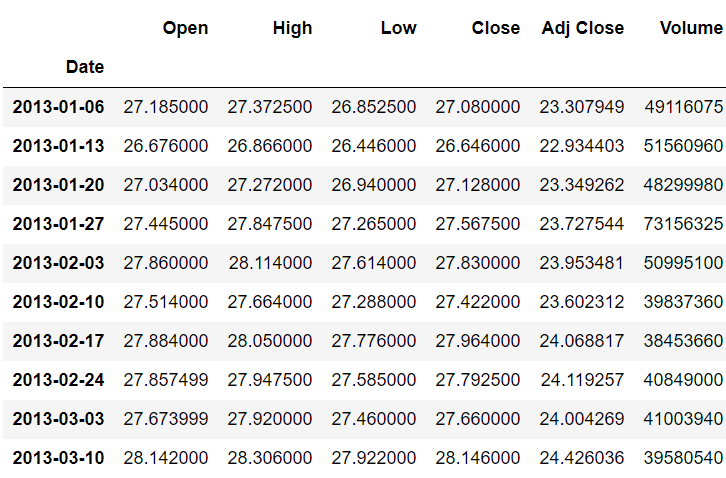
类似地,您可以使用以下脚本查找每周平均股票价格。(注意:周的偏移量为“W”。)
stock_data.resample(rule='W').mean()
输出:
使用时间重采样绘制图表
您还可以使用时间重采样绘制特定列的图表。查看以下脚本:
plt.rcParams['figure.figsize'] = (8, 6) # change plot size
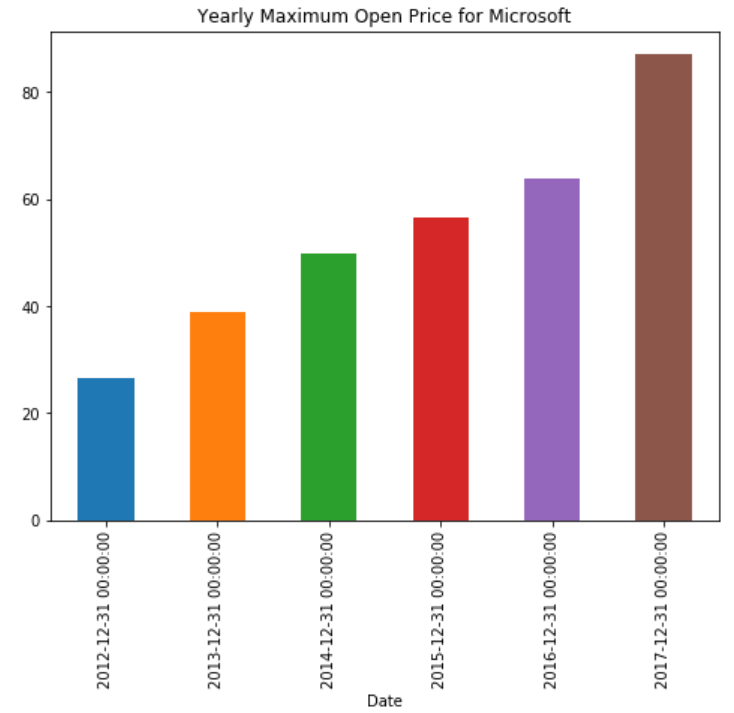
stock_data['Open'].resample('A').max().plot(kind='bar')
plt.title('Yearly Maximum Open Price for Microsoft')
上述脚本绘制了一个条形图,显示了股票的年度最高价格。您可以看到,重采样方法仅应用于 Open 列,而不是整个数据集。max () 和 plot() 函数链接在一起,以 1) 首先找到每年的最高开盘价,然后 2) 绘制条形图。输出如下所示:
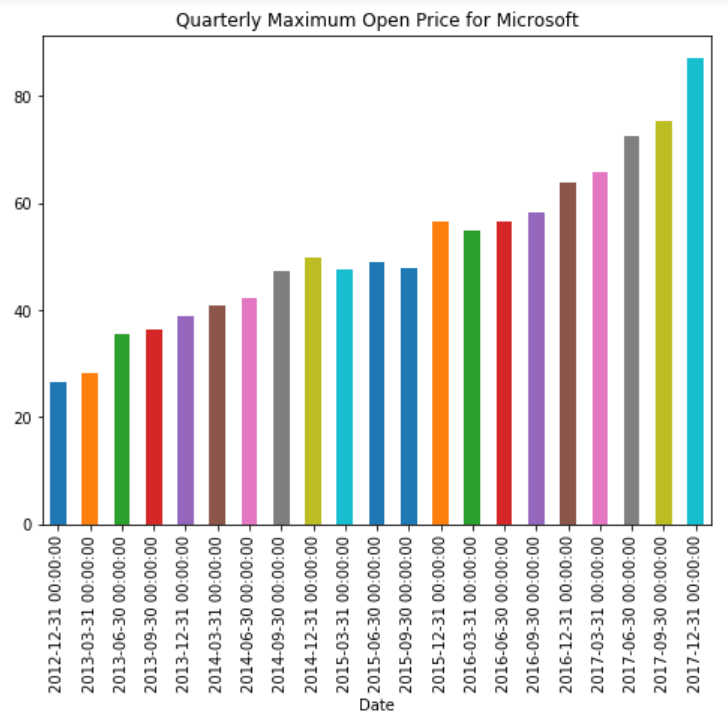
类似地,为了绘制季度最高开盘价,我们只需将偏移值设置为“Q”:
plt.rcParams['figure.figsize'] = (8, 6) # change plot size
stock_data['Open'].resample('Q').max().plot(kind='bar')
plt.title('Quarterly Maximum Open Price for Microsoft')
现在您可以看到微软的季度最高开盘股价:
时间转换
时间平移是指沿着时间索引向前或向后移动数据。让我们看看向前或向后移动数据是什么意思。
和 head() 查看数据集的前五行和后五行 tail() 。 head() 函数显示数据集的前五行,而 tail() 函数显示后五行。
执行以下脚本:
stock_data.head()
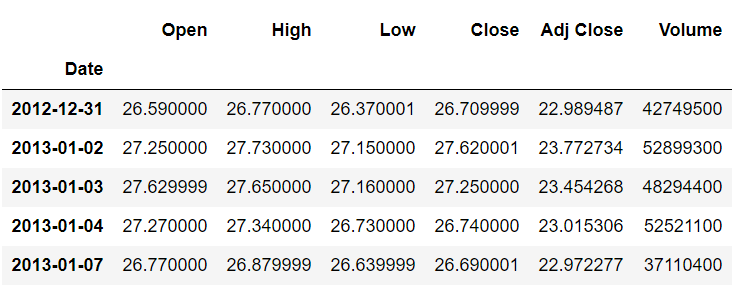
stock_data.tail()
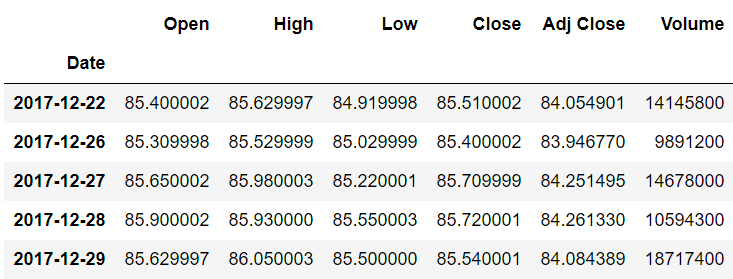
我们从数据集的头部和尾部打印了记录,因为当我们稍后移动数据时,我们会看到实际数据和移动后的数据之间的差异。
向前迈进
现在让我们进行实际的移动。要将数据向前移动,只需将要移动的索引数传递给 shift shift () 方法,如下所示:
stock_data.shift(1).head()
以前属于记录
Open
,
Close
,
Adjusted Close
的值
Volume
、 和
N
现在属于记录
N+1
。输出如下所示:
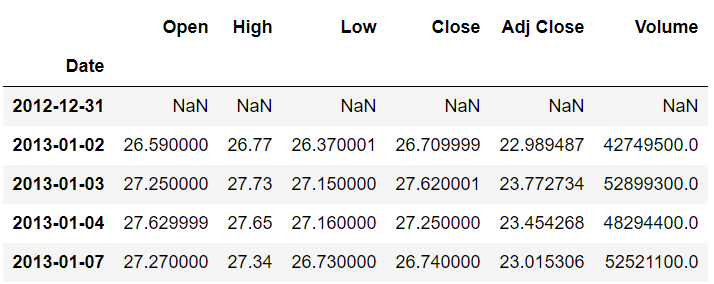
从输出中可以看到,第一个索引 (2012-12-31) 现在没有数据。第二个索引包含以前属于第一个索引 (2013-01-02) 的记录。
类似地,在尾部,您将看到最后一个索引(2017-12-29)现在包含以前属于倒数第二个索引(2017-12-28)的记录。如下所示:
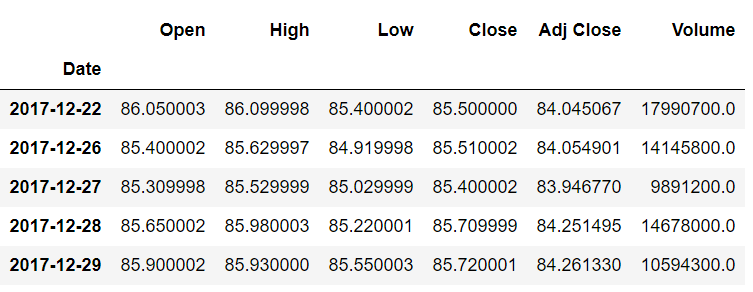
此前,Open 列值 85.900002 属于索引 2017-12-28,但向前移动一个索引后,它现在属于 2017-12-29。
向后移动
要将数据向后移动,请传递索引数以及减号。向后移动一个索引意味着
Open
,
Close
,
Adjusted Close
之前属于记录
Volume
、 和
N
现在属于记录
N-1
.
要后退一步,请执行以下脚本:
stock_data.shift(-1).head()
输出如下所示:
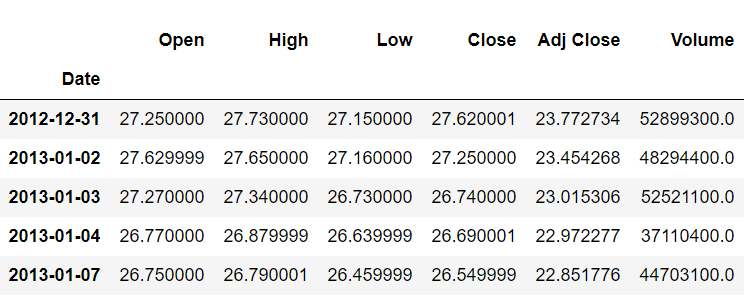
我们可以看到,向后移动一个指数后,开盘价 27.250000 属于指数 2012-12-31。之前,它属于指数 2013-01-02。
使用时间偏移移动数据
在时间重采样部分,我们使用了 p属性指定步长,而sas 偏移表中的偏移来指定重采样的时间段。我们也可以使用相同的偏移表进行时间移位。为此,我们需要传递 参数 and 和 属性指定步长的大小。例如,如果您想将数据向前移动两周,可以使用 , 。period period freq freq tshift() tshift() 如下所示:
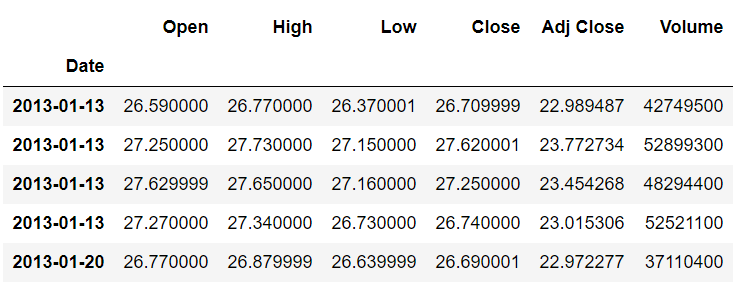
stock_data.tshift(periods=2,freq='W').head()
在输出中,您将看到数据向前移动了两周:
了解有关 Python 中时间序列数据的更多信息
时间序列分析是作为金融专家需要完成的主要任务之一,与投资组合分析和卖空一样。在本文中,您了解了如何使用 Python 的 pandas 库来可视化时间序列数据。您已经学习了如何执行时间采样和时间移位。但是,本文仅仅触及了 pandas 和 Python 进行时间序列分析的皮毛。Python 提供了更高级的时间序列分析功能,例如预测未来股票价格以及对时间序列数据执行滚动和扩展操作。
如果您有兴趣进一步了解用于时间序列分析和其他财务任务的 Python,我强烈建议您参加我们的 Python 数据科学 入门课程,以获得更多实践经验。




发表评论 取消回复