您已经掌握了一些用于数据科学的 Python 基础知识。但您能高效地编写代码吗?查看这些提示和技巧,以增强您的 Python 技能。
如何编写高效的 Python 代码
在本文中,我们将介绍一些有助于您
编写快速高效的 Python 代码
。我将从如何优化涉及
pandas
库的代码开始。如果您想复习 pandas 的知识,请查看我们的
“数据科学 Python 入门”
课程。
之后,我将继续介绍一些其他常见的 Python 最佳实践,包括列表推导、枚举器、字符串连接等。
1. 确定缺失数据的百分比
为了说明,我将使用一个 合成数据集 ,其中包含来自美国的 500 名虚构对象的联系信息。让我们想象一下这是我们的客户群。数据集如下所示:
clients.head()
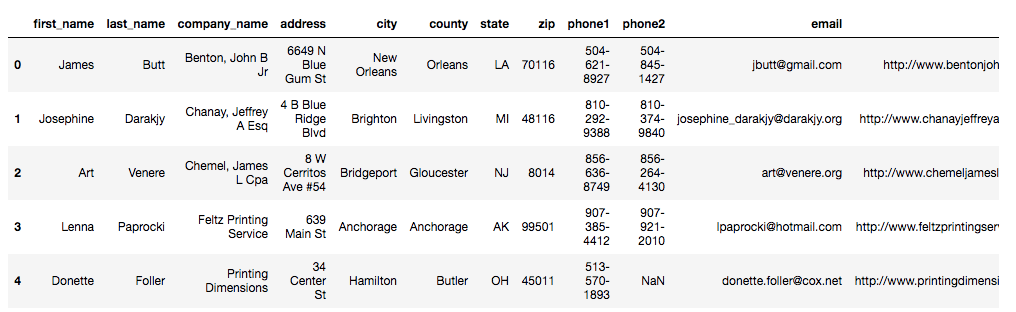
如您所见,它包含每个人的名字、姓氏、公司名称、地址、城市、县、州、邮政编码、电话号码、电子邮件和网址的信息。
我们的首要任务是检查缺失数据。您可以使用来
clients.info()
概览每列中完整条目的数量。但是,如果您想要更清晰的了解,以下是按降序获取每个特征的缺失条目百分比的方法:
# Getting percentange of missing data for each column (clients.isnull().sum()/clients.isnull().count()).sort_values(ascending=False)

您可能还记得,
isnull()
返回一个 True 和 False 值数组,分别指示给定条目是否存在或缺失。此外,当我们将此布尔对象传递给数学运算时,True 被视为 1,False 被视为 0。因此,
clients.isnull().sum()
给出了每列中缺失值的数量(True 值的数量),而
clients.isnull().count()
是每列中的值总数。
将第一个值除以第二个值,然后按降序对结果进行排序,即可得到每列缺失数据条目的百分比,从缺失值最多的列开始。在我们的示例中,我们发现 51.6% 的客户漏掉了第二个电话号码。
2. 寻找一组独特的价值观
有一种标准方法可以获取特定列的唯一值列表:
clients['state'].unique()
。但是,如果您拥有包含数百万个条目的庞大数据集,您可能更喜欢更快的选项:
# Checking unique values efficiently clients['state'].drop_duplicates(keep="first", inplace=False).sort_values()

这样,您便会删除所有重复项,并仅保留每个值的第一次出现。我们还对结果进行了排序,以检查每个州确实只被提及一次。
3. 连接列
通常,您可能需要使用特定分隔符连接多个列。以下是执行此操作的简单方法:
# Joining columns with first and last name clients['name'] = clients['first_name'] + ' ' + clients['last_name']
clients['name'].head()
如您所见,我们将
first_name
和
last_name
列合并为姓名列,其中名字和姓氏以空格分隔。
4. 拆分列
那么,如果我们需要拆分列怎么办?以下是使用数据条目中的第一个空格字符将一列拆分为两列的有效方法:
# Getting first name from the 'name' column
clients['f_name'] = clients['name'].str.split(' ', expand = True)[0]
# Getting last name from the 'name' column
clients['l_name'] = clients['name'].str.split(' ', expand = True)[1]
现在我们将名称的第一部分保存为
f_name
列,将名称的第二部分保存为单独的
l_name
列。
5. 检查两列是否相同
由于我们已经练习过合并和拆分列,您可能已经注意到,我们现在有两列包含名字(
first_name
和
f_name
)和两列包含姓氏(
last_name
和
l_name
)。让我们快速检查这些列是否相同。
首先,请注意,您可以使用它
equals()
来检查列甚至整个数据集是否相等:
# Checking if two columns are identical with .equals() clients['first_name'].equals(clients['f_name'])
True
您将得到一个
True
或
False
答案。但是如果您得到
False
并想知道有多少条目不匹配怎么办?以下是获取此信息的简单方法:
# Checking how many entries in the initial column match the entries in the new column (clients['first_name'] == clients['f_name']).sum()
500
匹配
的条目数
。在这里,我们再次利用 True 在计算中被视为 1 的事实。我们看到列中的 500 个条目与
first_name
中的条目匹配
f_name
。您可能还记得 500 是我们数据集中的总行数,因此这意味着所有条目都匹配。但是,您可能并不总是记得(或知道)数据集中的条目总数。因此,对于我们的第二个示例,我们
通过从总条目数中减去匹配条目数来
不匹配
# Checking how many entries in the initial column DO NOT match the entries in the new column clients['last_name'].count() - (clients['last_name'] == clients['l_name']).sum()
0
6. 分组数据
为了演示如何在 Pandas 中有效地对数据进行分组,我们首先创建一个包含电子邮件服务提供商的新列。在这里,我们可以使用您已经熟悉的拆分列的技巧:
# Creating new columb with the email service providers
clients['email_provider'] = clients['email'].str.split('@', expand = True)[1]
clients['email_provider'].head()

现在让我们按州对客户进行分组
email_provider
:
# Grouping clients by state and email provider
clients.groupby('state')['email_provider'].value_counts()

我们现在有一个数据框,它使用多层索引来提供对每个观察的访问(称为多索引)。
7. 拆开
有时,您可能希望将索引的一个级别(如
email_provider
)转换为数据框的列。这正是这样
unstack()
做的。最好用一个例子来解释这一点。那么,让我们解开上面的代码:
# Moving 'Mail providers' to the column names
clients.groupby('state')['email_provider'].value_counts().unstack().fillna(0)
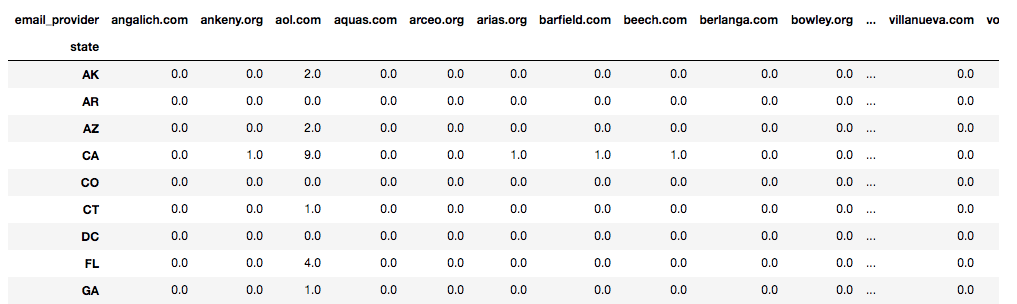
如您所见,电子邮件服务提供商的值现在是我们数据框的列。
现在是时候继续学习一些其他的 Python 技巧了
pandas
.
8. 使用列表推导
列表推导是 Python 的关键特性之一,你可能已经熟悉这个概念了。即使你熟悉,这里也简要提醒一下列表推导如何帮助我们更有效地创建列表。:
# Inefficient way to create new list based on some old list
squares = []
for x in range(5):
squares.append(x**2)
print(squares)
[0, 1, 4, 9, 16]
# Efficient way to create new list based on some old list squares = [x**2 for x in range(5)] print(squares)
[0, 1, 4, 9, 16]
9. 连接字符串
当您需要连接一串字符串时,可以 using a for loop and adding each element one by one 。但是,这样做效率很低,尤其是当列表很长时。在 Python 中,字符串是不可变的,因此每次连接时都必须将左右字符串复制到新字符串中。
更好的方法是使用
join()
如下所示的函数:
# Naive way to concatenate strings
sep = ['a', 'b', 'c', 'd', 'e']
joined = ""
for x in sep:
joined += x
print(joined)
abcde
# Joining strings sep = ['a', 'b', 'c', 'd', 'e'] joined = "".join(sep) print(joined)
abcde
10. 使用枚举器
你会如何打印一份世界上最富有的人的名单?也许你会考虑这样做:
# Inefficient way to get numbered list
the_richest = ['Jeff Bezos', 'Bill Gates', 'Warren Buffett', 'Bernard Arnault & family', 'Mark Zuckerberg']
i = 0
for person in the_richest:
print(i, person)
i+=1

但是,您可以使用以下函数以更少的代码完成相同的操作
enumerate()
:
# Efficient way to get numbered list
the_richest = ['Jeff Bezos', 'Bill Gates', 'Warren Buffett', 'Bernard Arnault & family', 'Mark Zuckerberg']
for i, person in enumerate(the_richest):
print(i, person)

当您需要遍历列表并跟踪列表项的索引时,枚举器非常有用。
11. 使用列表时使用 ZIP
现在,如果您需要组合几个长度相同的列表并打印出结果,您将如何进行?同样,这是一种更通用和
“Pythonic”的方法
,可以利用来获得所需的结果
zip()
:
# Inefficient way to combine two lists
the_richest = ['Jeff Bezos', 'Bill Gates', 'Warren Buffett', 'Bernard Arnault & family', 'Mark Zuckerberg']
fortune = ['$112 billion', '$90 billion', '$84 billion', '$72 billion', '$71 billion']
for i in range(len(the_richest)):
person = the_richest[i]
amount = fortune[i]
print(person, amount)

# Efficient way to combine two lists
the_richest = ['Jeff Bezos', 'Bill Gates', 'Warren Buffett', 'Bernard Arnault & family', 'Mark Zuckerberg']
fortune = ['$112 billion', '$90 billion', '$84 billion', '$72 billion', '$71 billion']
for person, amount in zip(the_richest,fortune):
print(person, amount)
该函数的可能应用
zip()
包括所有需要映射群组的场景(例如,员工及其工资和部门信息、学生及其成绩等)。
如果您需要回顾使用列表和字典的工作,您可以 在线 。
12. 交换变量
使用元组和打包/解包 在一行代码中交换变量 :
# Swapping variables) a = "January" b = "2019" print(a, b) a, b = b, a print(b, a)
January 2019 January 2019
包起来
太棒了!现在你已经熟悉了数据科学家在日常工作中使用的一些有用的 Python 技巧和窍门。这些技巧应该可以帮助你提高代码效率,甚至给你的潜在雇主留下深刻印象。
但是,除了使用不同的技巧之外,数据科学家还需要扎实的 Python 基础。
如果您需要复习,
“数据科学 Python 入门
matplotlib
”课程;它涵盖了 pandas 的基础知识和数据科学的关键 Python 库,以及使用 Python 处理数据所需的其他基本概念。




发表评论 取消回复