Python 是用于金融数据分析的最常用编程语言之一,具有大量有用的库和内置功能。在本文中,您将了解如何使用 Python 的机器学习库进行客户流失预测。
客户流失 是一个财务术语,指客户或顾客的流失——即客户停止与公司或企业互动。同样, 流失率 是客户或顾客在特定时间段内离开公司的比率。高于某个阈值的流失率会对公司的业务成功产生有形和无形的影响。理想情况下,公司希望留住尽可能多的客户。
随着先进的数据科学和机器学习技术的出现,公司现在可以识别可能在不久的将来停止与其开展业务的潜在客户。在本文中,您将了解银行如何根据年龄、性别、地理位置等不同客户属性预测客户流失。用于客户流失预测的功能的详细信息将在后面的部分中提供。
概述:使用 Python 进行客户流失预测
Python 附带各种数据科学和机器学习库,可用于根据数据集的不同特征或属性进行预测。Python 的 scikit-learn 库就是这样一种工具。在本文中,我们将使用此库进行客户流失预测。
数据集:银行客户流失模型
您可以从此 kaggle 链接 。请务必将 CSV 保存到您的硬盘上。
仔细观察,我们发现数据集包含 14 列(也称为 特征 或 变量 )。前 13 列是独立变量,最后一列是因变量,包含二进制值 1 或 0。其中,1 表示客户在 6 个月后离开银行的情况,0 表示客户在 6 个月后没有离开银行的情况。这被称为二元 分类问题 ,其中因变量只有两个可能的值 — 在这种情况下,客户要么在 6 个月后离开银行,要么不离开。
值得一提的是,独立变量的数据是在因变量的数据收集之前 6 个月收集的,因为任务是开发一个机器学习模型,该模型可以根据当前的特征值预测客户是否会在 6 个月后离开银行。
您可以使用 机器学习 分类算法来解决这个问题。
Note: All the code in this article is executed using Spyder IDE for Python .
以下是我们将在本文中采取的步骤的概述:
- 导入库
- 加载数据集
- 选择相关特征
- 将分类列转换为数字列
- 预处理数据
- 训练机器学习算法
- 评估机器学习算法
- 评估数据集特征
好啦,开始吧!
步骤 1:导入库
与往常一样,第一步是导入所需的库。执行以下代码即可完成此操作:
import numpy as np import matplotlib.pyplot as plt import pandas as pd
第 2 步:加载数据集
第二步是将本地 CSV 文件中的数据集加载到你的 Python 程序中。我们使用
read_csv
的方法
pandas
。执行以下代码:
customer_data = pd.read_csv(r'E:/Datasets/Churn_Modelling.csv')
如果您
customer_data
在 Spyder 的变量资源管理器窗格中打开数据框,您应该会看到如下所示的列:
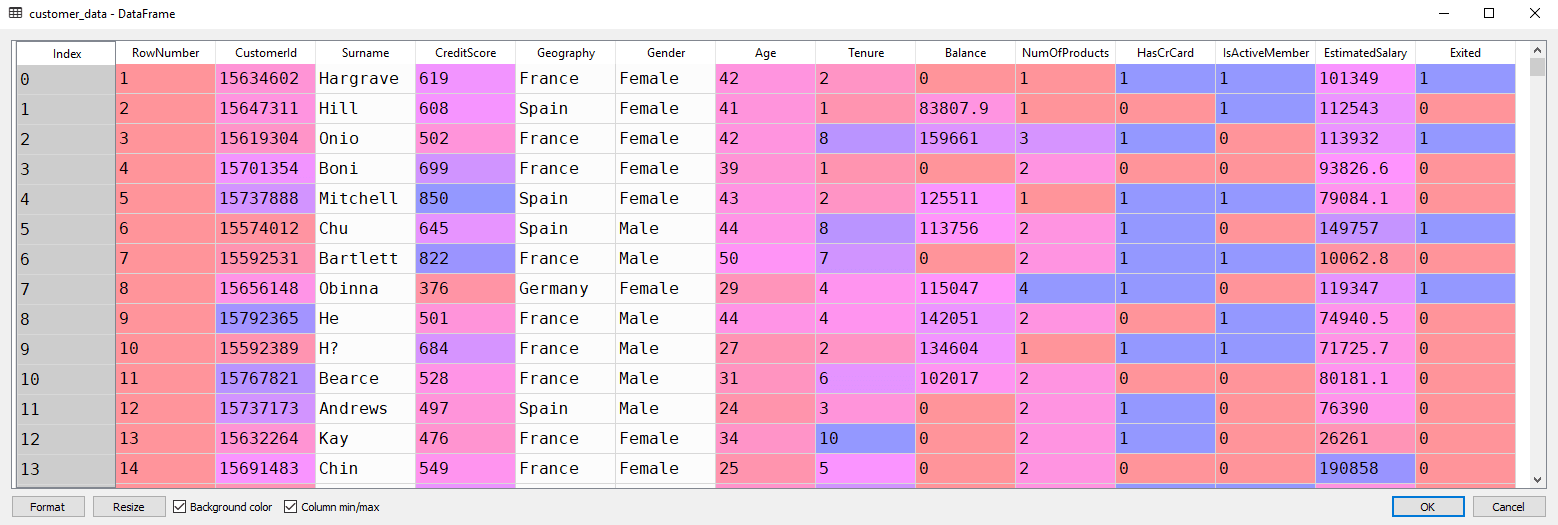
步骤3:特征选择
提醒一下,我们的数据集共有 14 列(见上图)。您可以通过执行以下代码来验证这一点:
columns = customer_data.columns.values.tolist() print(columns)
在输出中,您应该看到以下列表:
['RowNumber', 'CustomerId', 'Surname', 'CreditScore', 'Geography', 'Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard', 'IsActiveMember', 'EstimatedSalary', 'Exited']
并非所有列都会影响客户流失。让我们逐一讨论每一列:
-
RowNumber— 对应于记录(行)号,对输出没有影响。此列将被删除。 -
CustomerId— 包含随机值,对客户离开银行没有影响。此列将被删除。 -
Surname— 客户的姓氏不会影响他们离开银行的决定。此列将被删除。 -
CreditScore— 会对客户流失产生影响,因为信用评分较高的客户离开银行的可能性较小。 -
Geography— 客户的位置会影响他们离开银行的决定。我们将保留此专栏。 -
Gender— 探究性别是否影响客户离开银行是一件很有趣的事情。我们也会包含这个专栏。 -
Age——这当然是相关的,因为老年客户离开银行的可能性比年轻客户更小。 -
Tenure— 指客户成为银行客户的年数。通常,年长的客户更忠诚,并且不太可能离开银行。 -
Balance— 也是一个非常好的客户流失指标,因为与账户余额较低的人相比,账户余额较高的人离开银行的可能性较小。 -
NumOfProducts—指客户通过银行购买的产品数量。 -
HasCrCard— 表示客户是否拥有信用卡。此列也很重要,因为拥有信用卡的人不太可能离开银行。 -
IsActiveMember—活跃客户离开银行的可能性较小,因此我们会保留这一点。 -
EstimatedSalary— 与余额一样,与高薪人士相比,低薪人士更有可能离开银行。 -
Exited— 客户是否离开银行。这就是我们要预测的。
仔细观察这些特征后,我们将从特征集中删除
RowNumber
,
CustomerId
、和
Surname
列。所有剩余的列都会以某种方式导致客户流失。
要删除这三列,请执行以下代码:
dataset = customer_data.drop(['RowNumber', 'CustomerId', 'Surname'], axis=1)
请注意,我们已将过滤后的数据存储在名为 的新数据框中
dataset
。该
customer_data
数据框仍包含所有列。我们稍后会重复使用它。
步骤 4:将分类列转换为数字列
机器学习
算法最适合处理数值数据
。但是,在我们的数据集中,我们有两个分类列:
Geography
和
Gender
。这两列包含文本格式的数据;我们需要将它们转换为数字列。
首先,让我们从数据集中分离出这两列。执行以下代码即可完成此操作:
dataset = dataset.drop(['Geography', 'Gender'], axis=1)
将分类列转换为数字列的一种方法是将每个类别替换为数字。例如,在列中
Gender
,女性可以替换为 0,男性可以替换为 1,反之亦然。这适用于只有两个类别的列。
对于像地理这样的具有三个或更多类别的列,您可以使用值 0、1 和 2 来表示法国、德国和西班牙三个国家。但是,如果您这样做,机器学习算法将假设这三个国家之间存在 序数关系 。换句话说,算法将假设 2 大于 1 和 0,但就数字所代表的基础国家而言,情况实际上并非如此。
将此类分类列转换为数字列的更好方法是使用 独热编码 。在此过程中,我们采用类别(法国、德国、西班牙)并用列表示它们。在每一列中,我们使用 1 来表示当前行存在该类别,否则使用 0。
在这种情况下,有了法国、德国和西班牙这三个类别,我们可以只用两列(例如德国和西班牙)来表示分类数据。为什么?因为,如果对于给定的行,我们的地理区域是法国,那么德国和西班牙列都将为 0,这意味着该国必须是其余未由任何列表示的国家。请注意,我们实际上不需要为法国单独列一列。
我们将“地理”和“性别”列都转换为数字列。执行以下脚本:
Geography = pd.get_dummies(customer_data.Geography).iloc[:,1:] Gender = pd.get_dummies(customer_data.Gender).iloc[:,1:]
将
get_dummies
的方法
pandas
分类列转换为数字列。然后,
.iloc[:,1:]
忽略第一列并返回其余列(德国和西班牙)。如上所述,这是因为我们总是可以用“n - 1”列表示“n”个类别。
现在如果你在变量资源管理器窗格中打开
Geography
和
customer_data
数据框,你应该看到如下内容:
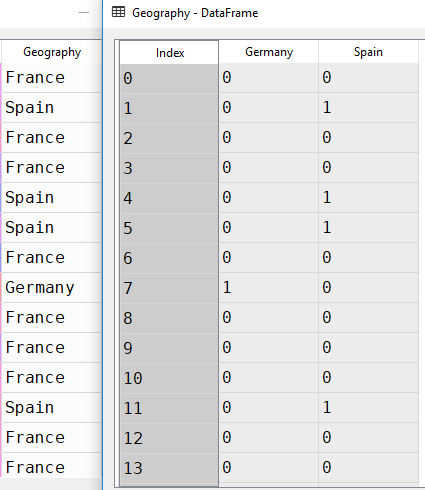
根据我们之前的解释,
Geography
数据框包含两列而不是三列。当地理位置为法国时,
Germany
和
Spain
包含 0。当地理位置为西班牙时,您可以在列中看到 1
Spain
,在列中看到 0。
Germany
同样,在 的情况下
Germany
,您可以在列中看到 1
Germany
,在列中看到 0
Spain
。
接下来,我们需要将
Geography
和
Gender
数据框添加回数据集以创建最终数据集。您可以使用
concat
中的函数
pandas
水平连接两个数据框,如下所示:
dataset = pd.concat([dataset,Geography,Gender], axis=1)
步骤5:数据预处理
我们的数据现在已经准备好了,我们可以训练我们的机器学习模型了。但首先,我们需要从数据集中分离出我们要预测的变量。
X = dataset.drop(['Exited'], axis=1) y = dataset['Exited']
这里,X 是我们的特征集;它包含除我们必须预测的列(
Exited
)之外的所有列。标签集 y 仅包含
Exited
列。
因此我们稍后可以评估机器学习模型的性能,我们还将数据分为训练集和测试集。训练集包含将用于训练机器学习模型的数据。测试集将用于评估模型的好坏。我们将使用 20% 的数据作为测试集,其余 80% 作为训练集(使用参数指定
test_size
):
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
第 6 步:机器学习算法训练
现在,我们将使用机器学习算法来识别训练数据中的模式或趋势。此步骤称为 算法训练 。我们将特征和正确的输出输入到算法中;基于该数据,算法将学会找到特征和输出之间的关联。训练算法后,您将能够使用它对新数据进行预测。
有几种机器学习算法可用于进行此类预测。不过,我们将使用 随机森林算法 是分类问题 最强大的算法之一 .
为了训练该算法,我们调用该
fit
方法并传入特征集 (X) 和相应的标签集 (y)。然后,您可以使用预测方法对测试集进行预测。查看以下脚本:
from sklearn.ensemble import RandomForestClassifier classifier = RandomForestClassifier(n_estimators=200, random_state=0) classifier.fit(X_train, y_train) predictions = classifier.predict(X_test)
步骤7:机器学习算法评估
现在算法已经训练完毕,是时候看看它的表现了。为了评估分类算法的性能,最常用的指标是 F1 度量、精度、召回率和准确率 。在 Python 的 scikit-learn 库中,您可以使用内置函数来查找所有这些值。执行以下脚本:
from sklearn.metrics import classification_report, accuracy_score print(classification_report(y_test,predictions )) print(accuracy_score(y_test, predictions ))
输出如下所示:
precision recall f1-score support
0 0.89 0.95 0.92 1595
1 0.73 0.51 0.60 405
avg / total 0.85 0.86 0.85 2000
0.8635
结果表明准确率为 86.35% ,这意味着我们的算法成功预测客户流失的概率为 86.35%。对于首次尝试来说,这已经相当令人印象深刻了!
步骤 8:特征评估
最后一步,让我们看看哪些特征在识别客户流失方面发挥了最重要的作用。幸运的是,
RandomForestClassifier
包含一个名为的属性
feature_importance
,其中包含有关给定分类的最重要特征的信息。
以下代码创建了预测客户流失的十大特征的条形图:
feat_importances = pd.Series(classifier.feature_importances_, index=X.columns) feat_importances.nlargest(10).plot(kind='barh')
输出如下:
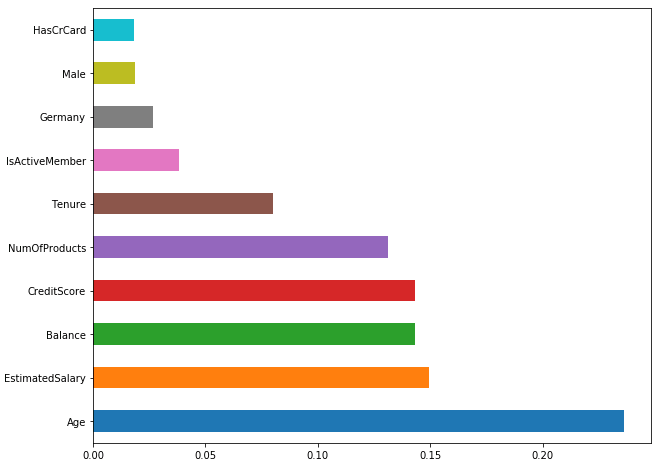
根据这些数据,我们可以看到,年龄对客户流失的影响最大,其次是客户的预计工资和账户余额。
结论
客户流失预测对于公司的长期财务稳定至关重要。在本文中,您成功创建了一个机器学习模型,该模型能够以 86.35% 的准确率预测客户流失。您可以看到为分类任务创建机器学习模型是多么简单和直接。
有兴趣探索 Python 在财务数据分析方面的其他应用吗?参加我们的 Python Basics 课程,获得更多实践经验。





发表评论 取消回复