有时你需要一个随机数或元素。Python 如何提供帮助?
事实上,随机性无处不在。想想彩票、掷骰子,或者办公室秘密圣诞老人活动的(极端)随机性。
在本文中,我们将讨论伪随机性、它与真随机性的区别以及如何在 Python 中应用它来生成随机数。我们还将深入研究一些更高级的主题,例如使用随机数进行可重复编码以及使用 choice () 和 choice() 函数从列表中返回随机字符串元素。最后,我们将向您展示如何随机化列表顺序。

什么是伪随机数?
伪随机数生成器借助数学算法产生“随机性”。这意味着随机选择是由计算机程序产生的。对人类来说,这具有随机性的效果:结果看起来完全是任意的。伪随机数生成器几乎与真随机数生成器(使用不可预测的物理方法生成随机数的生成器)一样好。
就本文而言,当我们谈论 Python 产生的随机性时,我们实际上谈论的是伪随机性。值得一提的是,我们不会使用真正的随机生成器,但伪随机性足以满足大多数商业世界当前的需要。
使用 Python 的随机模块生成伪随机数
Python 中用于生成随机数的最著名模块之一是 random 。让我们来看看这个库中最著名的函数。

选取一个随机整数
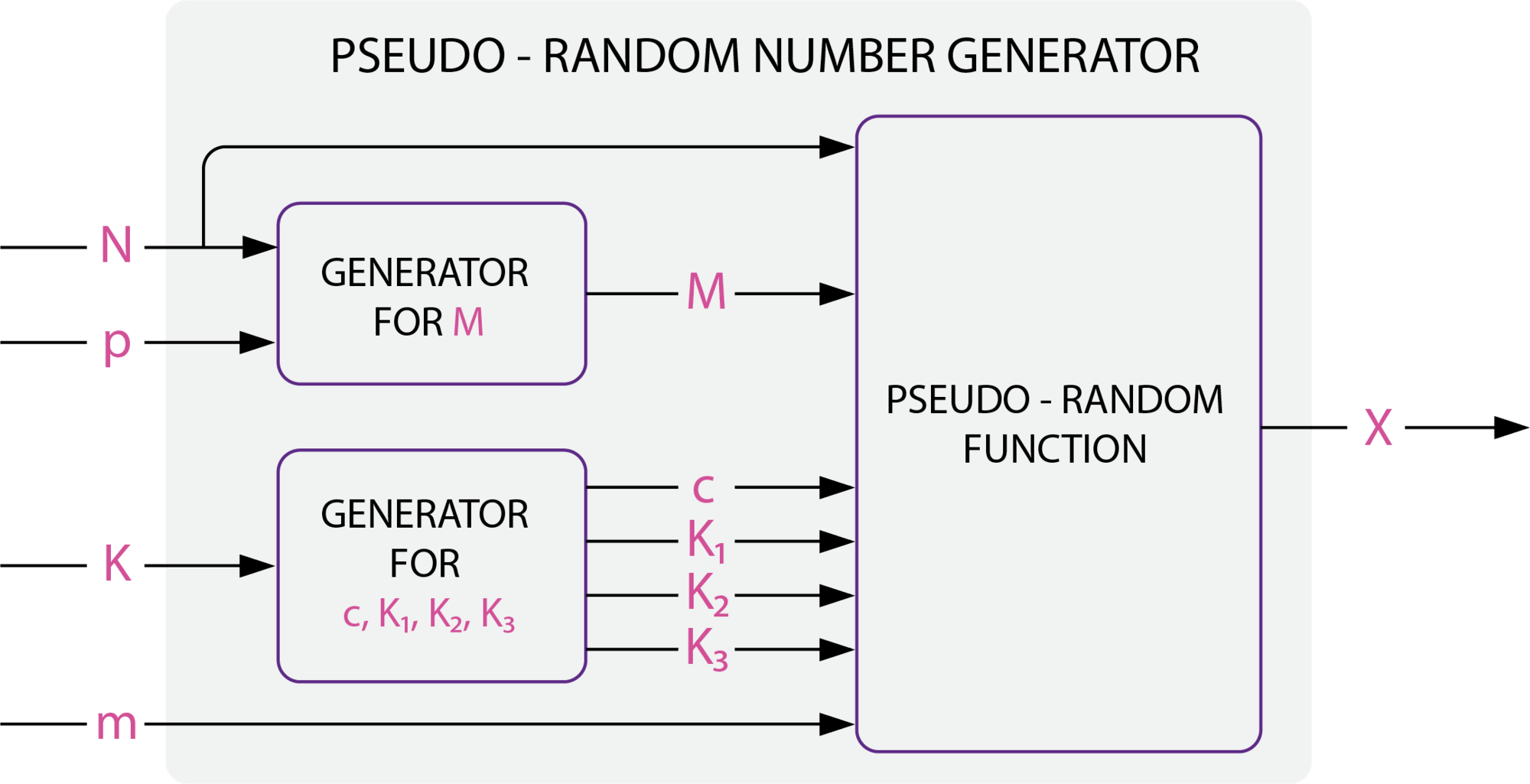
假设您从事销售工作,有 10 个客户。您想随机选择其中一个客户,以提供特别优惠。您可以使用 Python 中的 randint() 函数进行随机选择。
我们创建了一个示例——10 个客户存储在一个 Pandas 数据框中。每个客户都有一个 ID 和一个名称。ID 号从 0 到 10,可唯一标识每个客户。
import pandas as pd
clients = pd.DataFrame()
clients['client_id'] = [0,1,2,3,4,5,6,7,8,9]
clients['client_name'] = ["Mobili Ltd.","Tymy Ltd.", "Lukas Ltd.","Brod Ltd.",
"Missyda Ltd.", "Abiti Ltd.", "Bomy Ltd." , "Citiwi Ltd.", "Dolphy Ltd.", "Doper Ltd."]现在出现了一个问题:我们如何使用 randint() 从数据框中选择一个客户?很简单:
import random
random_number = random.randint(0,9)
clients.loc[clients['client_id'] == random_number]在上面的代码中, randint() 使用两个参数调用:起始数字(在本例中为 0)和结束数字(为 9)。通过使用参数 0 和 9 调用 randint() ,我们告诉 Python 从 0、1、2、3、4、5、6、7、8、9 中返回一个随机整数。调用 clients.loc[clients['client_id']== random_number] 将返回随机选择的客户端 ID 和关联名称:
尝试重复此过程几次。您不会总是获得相同的客户端,因为 ID 是由 随机 模块随机选择的。
但是,如果你想让你的代码可重现,该怎么办?也许你的老板想知道 Bomy Ltd. 是如何被选中的。也许他想运行代码并再次获得相同的结果。这是可能的,因为 random 模块生成的是伪随机数,而不是真正的随机数。Python 中随机生成的数字是可以确定的。(选择背后有一个数学公式)。 如果我们想获得可重现的结果, seed()
使用 seed() 函数进行可重复的编码

图片来源:Jorge Cham 所著《Piled Higher and Deeper》中的“Scratch”www.phdcomics.com 。
seed () 函数用于保存 random() 函数的状态,允许它在相同或不同的机器上针对特定种子值多次执行代码时生成相同的随机数。将相同的种子传递给 random() 然后调用该函数将始终为您提供相同的数字集。
如果我们将 random.seed(0) 上面例子中代码的开头,调用 randint(0,9) 将始终得到相同的结果:
import random
random.seed(0)
random.randint(0,9)使用 seed() 使您的代码可重现;每次执行都会产生相同的结果。
随机浮点数生成器
另一个有用的函数 random() 可用于随机浮点数生成器。
当今许多著名算法都在其中的一个步骤中使用伪随机浮点数生成器。例如,在 神经网络 , weights 重用较小的随机数初始化。其思想是找到一组完美的权重,特定映射函数将使用该权重对输出变量做出良好的预测。找到此类权重的过程称为“学习”;尝试多次迭代权重组合,并借助一种称为“随机梯度下降”的算法选择最佳组合(即,能够给出最准确预测的权重集)。
上述过程的第一步是使用随机生成的浮点数。可以借助 random() 函数来选择它们。因此,如果您需要生成一个小数字(介于 0 和 1 之间),则可以调用 random() :
import random
random.random()这将产生一个随机数 - 在我们的例子中为 0.5417604303861212。
返回的随机数始终在 0 到 1 之间。如果您想要从其他区间获取数字,只需将结果相乘即可。以下代码将始终生成 0 到 10 之间的随机数:
import random
random.random() * 10如果您想从特定间隔中选择一个随机数,还有另一种选择。这是 uniform() 函数,它接受两个参数: low (间隔的最低边界)和 high (间隔的最高边界)。
如果要选择一个介于 0 和 10 之间的随机数,可以使用 uniform() :
import random
radom.uniform(0,10)现在我们已经向您展示了 r和om() and uniform() ,您可以使用哪个函数。两者都可用于获取一定范围内的随机数。
但是,如果你想从元组或预定义列表中随机选择一个元素,该怎么办?还有一个函数可以做到这一点 - 它被称为 choice() 。当你想从给定列表中随机选择一个项目时,可以使用此函数。让我们看看它是如何工作的。
使用 choice() 从列表中返回随机元素

之前,我们举了一个例子,一个销售员需要从列表中选择一个客户。每个客户都用 0 到 10 之间的一个整数表示。我们的销售员不用 randint() 来选择随机整数,而是直接使用 choice() 函数,如下所示:
import random
import pandas as pd
clients = pd.DataFrame()
clients['client_id'] = [0,1,2,3,4,5,6,7,8,9]
clients['client_name'] = ["Mobili Ltd.","Tymy Ltd.", "Lukas Ltd.","Brod Ltd.",
"Missyda Ltd.", "Abiti Ltd.", "Bomy Ltd." , "Citiwi Ltd.", "Dolphy Ltd.", "Doper Ltd."]
clients.loc[clients['client_id'] == random.choice(clients['client_id'])]在上面的代码中, random.choice(clients['client_id']) 从列表 [0,1,2,3,4,5,6,7,8,9] 。 行 clients.loc[clients['client_id'] == random.choice(clients['client_id'])] random.choice(['clients_id']) 随机选择的客户名称和 ID 。 这是一种非常优雅的检索随机项目的方法。
值得一提的是, () 也适用于字符串列表。我们的销售员也可以 random. choice (clients['client_name']) 输出中会直接返回一个随机名称。choice choice() 不会随机选择整数,而是随机选择字符串。
有时您可能想从列表中选择多个项目。这可以通过 choices() 函数(注意“s”)来完成。我们可以使用 random.choices(clients['client_name'],k=2) 。k参数用于定义我们要随机选择的元素数量。
上述代码将返回两个随机选择的名称——请记住,如果您想使代码可重现,则必须使用 seed() 函数。(否则,您将始终得到不同的名称。)
import random
import pandas as pd
clients = pd.DataFrame()
clients['client_id'] = [0,1,2,3,4,5,6,7,8,9]
clients['client_name'] = ["Mobili Ltd.","Tymy Ltd.", "Lukas Ltd.","Brod Ltd.",
"Missyda Ltd.", "Abiti Ltd.", "Bomy Ltd." , "Citiwi Ltd.", "Dolphy Ltd.", "Doper Ltd."]
random.choices(clients['client_name'],k=2)使用 shuffle() 随机重新排序列表

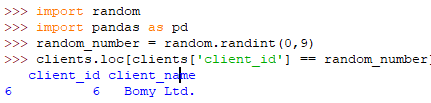
我们要提到的最后一个函数是 shuffle() 。当您需要以不同的顺序返回列表中的所有元素时,可以使用此函数。也许我们的销售员想打乱他的客户列表,并使用重新排序的列表进行销售电话。如下 列表 client_ids 所示: [0,1,2,3,4,5,6,7,8,9] 。可以使用 random.shuffle(client_id) 对其 。执行此行代码后,变量 client_id 看起来将类似于 [0, 4, 3, 2, 8, 9, 1, 6, 7, 5] 。我们随机打乱了列表。现在我们的销售员可以通过这种随机重新排序进行打电话。
对字符串列表进行重新排序 shuffle() 。如果我们将名称存储在列表中,如下所示:
client_name(['Mobili Ltd.'、'Tymy Ltd.'、'Lukas Ltd.'、'Brod Ltd.'、'Missyda Ltd.'、'Abiti Ltd.'、'Bomy Ltd.'、'Citiwi Ltd.' 、“Dolphy 有限公司”、“Doper 有限公司”])
我们可以通过运行 random.shuffle(client_name) 。它返回一个随机列表。
import random
client_name= ["Mobili Ltd.","Tymy Ltd.", "Lukas Ltd.","Brod Ltd.", "Missyda Ltd.", "Abiti Ltd.", "Bomy Ltd." , "Citiwi Ltd.", "Dolphy Ltd.", "Doper Ltd."]
random.shuffle(client_name)
client_name调用 random.shuffle() ,列表被重新排序。它看起来是这样的:
['Abiti Ltd.'、'Citiwi Ltd.'、'Dolphy Ltd.'、'Tymy Ltd.'、'Doper Ltd.'、'Missyda Ltd.'、'Mobili Ltd.'、'Lukas Ltd.'、'布罗德有限公司”、“博美有限公司”]
Python 中的随机数比你想象的要简单
最流行的 Python 模块之一使伪随机数生成变得简单。random 模块中最常用的一些函数包括处理随机整数选择 ( randint() )、随机浮点数 ( random() , uniform() )、随机列表项选择 ( choice() , choice() ) 和随机列表重新排序 ( shuffle() ) 的函数。本文向您展示了如何使用这些函数以及如何在代码中实现随机性。请记住,当您使用 seed() ,这些伪随机结果可以在您的代码中重现 - 这是一种在 Python 中实现随机数的非常方便的方法!





发表评论 取消回复