如果您已经具备一些 Python 经验,那么建立自己的数据科学项目组合是向潜在雇主展示您的技能的最佳方式。但是,您从哪里开始开发您的第一个 Python 项目呢?
首先,为什么要开发数据科学项目?
使用 Python 等语言创建自己的数据科学项目可以带来许多职业发展益处:
- 学习。 最好的学习方式是边做边学。当然,如果你是一个完全的初学者,你可能需要先学习一些 入门课程 来了解 Python 的基础知识。之后,你可以通过定义一个有趣的问题并使用在线教程、文档和论坛来解决问题,从而自学。
- 练习。 项目是练习您已掌握技能的绝佳机会。通过开发自己的项目,您可以将新获得的知识应用于一些实际任务。这也是测试自己的好机会——您准备好从头开始创建自己的项目了吗?
- 展示你的技能。 即使是入门级职位,数据科学公司也往往更喜欢至少接触过 Python 等语言的候选人。项目是展示你的数据科学技能的最佳方式。
- 展现你的积极性和奉献精神。 当你在没有任何外部激励的情况下完成自己的项目时,它向你的潜在雇主表明你真的热衷于从事数据科学事业。从雇主的角度来看,自我激励的员工是一项很好的投资。
当然,如果你选择一个好的项目,你也会玩得很开心。任何喜欢编程的人都会告诉你,没有什么感觉比亲自动手解决现实生活中的问题更有趣了。
创建自己的数据科学项目的 5 个步骤
准备好开始了吗?我们将在这个小型示例项目中介绍以下步骤:
- 定义项目
- 准备数据
- 探索和可视化数据
- 创建机器学习模型
- 展示你的发现
1. 定义项目
每个数据科学项目都始于一个明确的目标:你想通过这个项目实现什么目标?在为你的投资组合开发第一个 Python 项目时,你可以应用类似的逻辑:你想通过这个项目展示什么技能?
雇主寻求的数据科学技能包括但不限于:
- 数据清理和整理
- 探索性数据分析
- 机器学习
- 临床结果解读
例如,为了展示你的数据清理技能,你可以获取一些现实世界的杂乱数据并准备进行分析。如果你想练习探索性数据分析和机器学习,可以找到一些已经预处理并准备进行分析的在线数据集。
我们将采用第二种方法,这使我们能够更有效地展示开发数据科学项目的原则。因此,我们将使用著名的 波士顿住房 数据集,该数据集可在线获取,但也可以从 scikit-learn 库中加载。使用流行数据集的一个好处是,在项目结束时,您将能够看到您的模型与其他模型相比的表现如何——只需查看 Kaggle 的排行榜 .
该探索性项目的目标是使用数据集中的 13 个特征(例如犯罪率、地区人口、每户房间数)和 506 个样本来预测房价。
2.准备数据
我们将首先导入以下数据分析和可视化库:
- NumPy
- 熊猫
- Matplotlib
- 西博恩
如果你不熟悉其中任何一个,我们将在 Python 入门课程 .
# Importing libraries import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline
下一步是 从 波士顿住房 scikit-learn 并探索其内容:
# Loading dataset from sklearn.datasets import load_boston boston_housing = load_boston() print(boston_housing.keys())
dict_keys(['data', 'target', 'feature_names', 'DESCR'])
从键列表中可以看出,数据集包含数据(13 个特征的值)、目标(房价)、
feature
名称和
DESCR
(描述)。
在描述中,您将找到对该数据集所有特征的详尽解释:
print (boston_housing.DESCR)
Boston House Prices dataset =========================== Notes ------ Data Set Characteristics: :Number of Instances: 506 :Number of Attributes: 13 numeric/categorical predictive :Median Value (attribute 14) is usually the target :Attribute Information (in order): - CRIM per capita crime rate by town - ZN proportion of residential land zoned for lots over 25,000 sq.ft. - INDUSproportion of non-retail business acres per town - CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise) - NOXnitric oxides concentration (parts per 10 million) - RM average number of rooms per dwelling - AGEproportion of owner-occupied units built prior to 1940 - DISweighted distances to five Boston employment centres - RADindex of accessibility to radial highways - TAXfull-value property-tax rate per $10,000 - PTRATIOpupil-teacher ratio by town - B1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town - LSTAT% lower status of the population - MEDV Median value of owner-occupied homes in $1000's :Missing Attribute Values: None
现在是时候创建一个
DataFrame
包含所有特征和目标变量的了:
# Creating dataframe with features boston_df = pd.DataFrame(boston_housing.data, columns = boston_housing.feature_names) # Adding target variable to the dataset boston_df['MEDV'] = boston_housing.target boston_df.head()
桌子

第一步,我们创建一个
DataFrame
仅具有特征的模型,然后添加一个目标变量——房价(
MEDV
)。
和
info()
检查新数据集始终是一个好主意
describe()
。
boston_df.info()
RangeIndex: 506 entries, 0 to 505 Data columns (total 14 columns): CRIM 506 non-null float64 ZN 506 non-null float64 INDUS506 non-null float64 CHAS 506 non-null float64 NOX506 non-null float64 RM 506 non-null float64 AGE506 non-null float64 DIS506 non-null float64 RAD506 non-null float64 TAX506 non-null float64 PTRATIO506 non-null float64 B506 non-null float64 LSTAT506 non-null float64 MEDV 506 non-null float64 dtypes: float64(14) memory usage: 55.4 KB
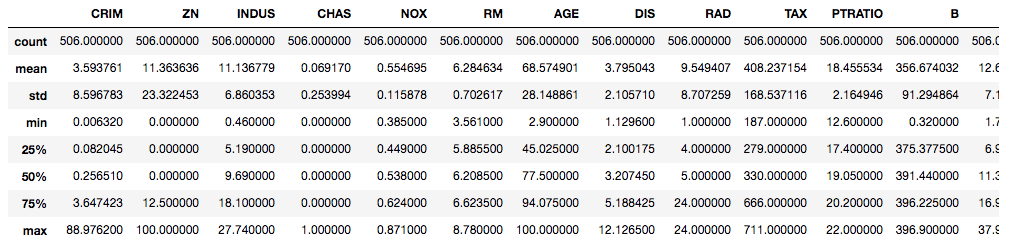
boston_df.describe()
桌子
太棒了!您已经演示了如何创建
DataFrame
和准备原始数据以供分析。现在让我们继续进行一些探索性数据分析。
3. 探索和可视化数据
由于这是一个旨在向潜在雇主展示您的技能的数据科学项目,因此您可能需要绘制不同类型的多个图表,以直观易懂的格式显示您的数据。
价格分布。 我们可以先看看目标变量(房价)的分布:
sns.set_style(\"darkgrid\") plt.figure (figsize=(10,6)) # Distribution of the target variable sns.distplot(boston_df['MEDV'], axlabel = 'Median value of owner-occupied homes in $1000')
阴谋
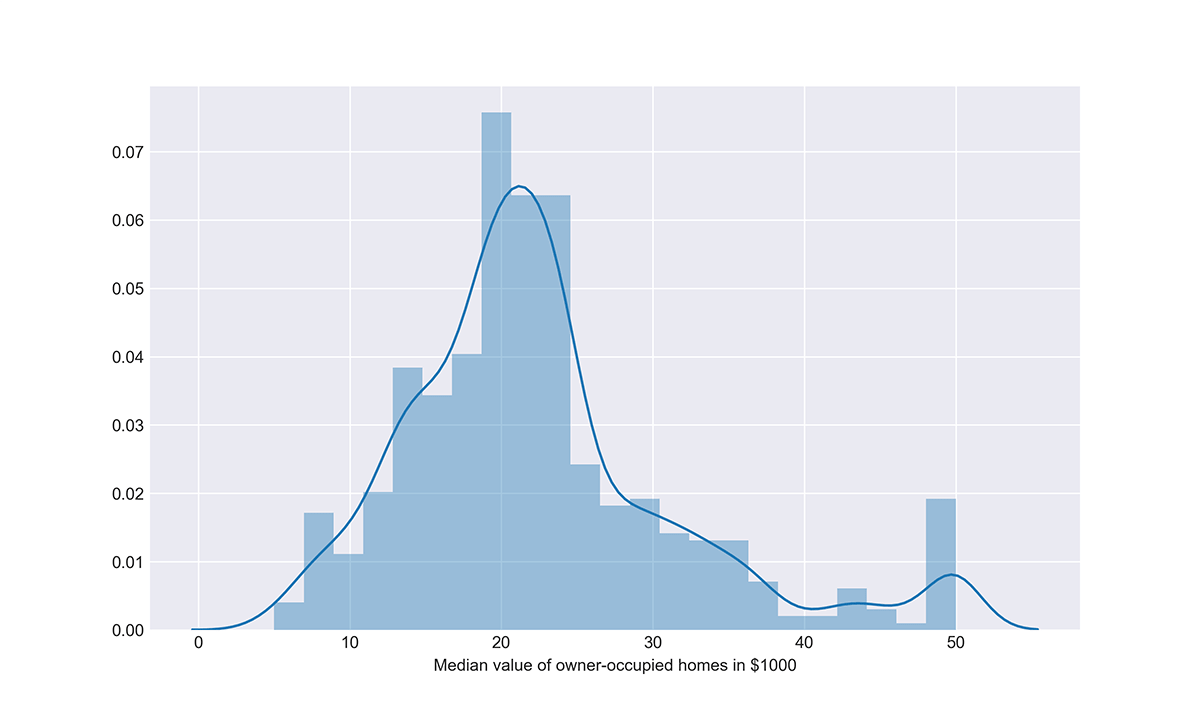
该图显示,20 世纪 70 年代波士顿地区的房屋价值平均为 20-25 万美元,最低为 5 千美元,最高为 5 万美元。
相关矩阵。
现在让我们看看这个目标变量如何与我们的特征相关,以及我们的特征如何相互关联。对于这个任务,我们首先创建一个
DataFrame
具有相关性的新矩阵,然后使用热图将其可视化:
# Correlation matrix boston_corr = boston_df.corr() plt.figure (figsize=(10,6)) sns.heatmap(boston_corr, annot = True, cmap = 'coolwarm')
阴谋

该相关矩阵显示房屋的中位数(
MEDV
)具有:
-
与较低地位人口比例 (
LSTAT) 呈强烈负相关 (-0.74)。 -
与每套住宅的平均房间数 (
RM) 呈强正相关 ( 0.7 )。
联合图。 现在,我们可以使用 seaborn 库中的联合图更深入地研究这些变量之间的关系。这些图显示了每个变量的分布以及变量之间的关系。例如,让我们检查一下房价是否可能线性依赖于该地区低社会地位人口的比例:
# Jointplots for high correlations - lower status population plt.figure (figsize=(10,10)) sns.jointplot(x = 'LSTAT', y = 'MEDV', data = boston_df, kind = 'reg', size = 10, color = 'orange')
阴谋

通过使用可选
reg
参数,我们可以看到线性回归模型与数据的拟合程度。在这种情况下,我们对变量(
LSTAT
和
MEDV
)之间线性关系的假设非常合理,因为数据点似乎位于一条直线上。
我们还可以使用其他类型的联合图来可视化两个变量之间的关系。让我们使用六边形联合图来研究房价与房间数量之间的关系:
# Jointplots for high correlations - number of rooms plt.figure (figsize=(10,10)) sns.jointplot(x = 'RM', y = 'MEDV', data = boston_df, kind = 'hex', color = 'green', size = 10)
阴谋

从上图可以看出,样本案例包括许多有 6 个房间且价格在 2 万美元左右的房屋。此外,从此可视化中可以清楚地看出,房间数量越多,价格越高。这种关系可以用线性回归模型来近似。
您可以考虑其他方法来进一步探索此数据集。但与此同时,让我们继续进行项目的机器学习部分。具体来说,让我们看看如何模拟特征和目标变量之间的关系,以便模型对房价的预测尽可能准确。
4.创建机器学习模型
首先,我们需要为项目的这一部分准备数据集。具体来说,我们需要将特征与目标变量分开,然后将数据集分为训练集(75%)和测试集(25%)。我们将在训练集上训练我们的模型,然后在看不见的数据(测试集)上评估它们的性能。
# Preparing the dataset X = boston_df.drop(['MEDV'], axis = 1) Y = boston_df['MEDV']
# Splitting into training and test sets from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.25, random_state=100)
线性回归。 现在,我们准备训练第一个模型。我们将从最简单的模型——线性回归开始:
# Training the Linear Regression model from sklearn.linear_model import LinearRegression lm = LinearRegression() lm.fit(X_train, Y_train)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
在上面的代码中,我们
LinearRegression
从
scikit-learn
库导入了模型并在我们的数据集上对其进行了训练。现在让我们使用两个常见指标来评估该模型:
-
根均方误差 (
RMSE) -
R 平方(
r2_score)
# Evaluating the Linear Regression model for the test set
from sklearn.metrics import mean_squared_error, r2_score
predictions = lm.predict(X_test)
RMSE_lm = np.sqrt(mean_squared_error(Y_test, predictions))
r2_lm = r2_score(Y_test, predictions)
print('RMSE_lm = {}'.format(RMSE_lm))
print('R2_lm = {}'.format(r2_lm))
RMSE_lm = 5.213352900070844 R2_lm = 0.7245555948195791
该模型给出的
RMSE
R 平方值为 5.2。此外,R 平方值为 0.72 意味着该
线性模型
解释了总响应变量变化的 72%。对于第一次尝试来说,这还不错。让我们看看我们能否使用另一个模型实现更好的性能。
随机森林。 这是一种更高级的算法,但它在 Python 中的实现仍然相当简单。您可能想要试验估算器的数量,并设置一些随机状态以获得一致的结果:
# Training the Random Forest model from sklearn.ensemble import RandomForestRegressor rf = RandomForestRegressor(n_estimators = 10, random_state = 100) rf.fit(X_train, Y_train)
RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1, oob_score=False, random_state=100, verbose=0, warm_start=False)
# Evaluating the Random Forest model for the test set
predictions_rf = rf.predict(X_test)
RMSE_rf = np.sqrt(mean_squared_error(Y_test, predictions_rf))
r2_rf = r2_score(Y_test, predictions_rf)
print('RMSE_rf = {}'.format(RMSE_rf))
print('R2_rf = {}'.format(r2_rf))
RMSE_rf = 3.4989580001214895 R2_rf = 0.8759270334224734
看来
随机森林
波士顿住房
的更好的模型
:误差较低(
RMSE
= 3.5),解释变异的份额明显较高(R 平方为 0.88)。
5. 展示你的发现
就这样!现在是时候与全世界分享你的项目了。
如果您使用 Jupyter Notebook 作为 Python IDE,您可以直接共享笔记本,但最好将其保存为 PDF 文件,以便更方便访问。另一种选择是通过 GitHub 共享您的 Python 项目。
不要忘记对你的发现进行广泛的评论。绘制吸引人且有意义的图表或构建机器学习模型是重要的技能,但数据科学家应该能够根据使用的所有图表和模型讲述一个故事。因此,利用你的每个项目作为一个机会来展示你发现模式和根据原始数据得出结论的技能。
如果您觉得在使用 Python 开发第一个项目之前需要更多指导,请查看我们的“ 数据科学 Python 简介” 课程。它涵盖了不仅在学习过程中而且在解决工作场所中的一些实际问题时开发成功项目所需的许多概念。





发表评论 取消回复